[DG][OD] CLIP the Gap: A Single Domain Generalization Approach for Object Detection
[DG][OD] CLIP the Gap: A Single Domain Generalization Approach for Object Detection
-
git : https://github.com/vidit09/domaingen
-
paper : https://arxiv.org/pdf/2301.05499.pdf
-
target downstream task : Single Source Domain Generalization for Object Detection
-
Contribution
- Vision-Language Model Clip의 pretrained text-image alignment feature를 활용해서 예상되는 source domain text 문구 (ex, sunny normal day)와 target domain text 문구 (ex. rainy cloudy day)의 text embedding 정보를 visual prompt로 활용해서 source domain을 target domain으로 transform하는 학습에 활용한다.
- 논문에서는 이를 augmentation으로 설명했으나, 제가 보기엔 text prompt 를 학습하는 prompt learning의 일종으로 생각됩니다.
-
overall architecture
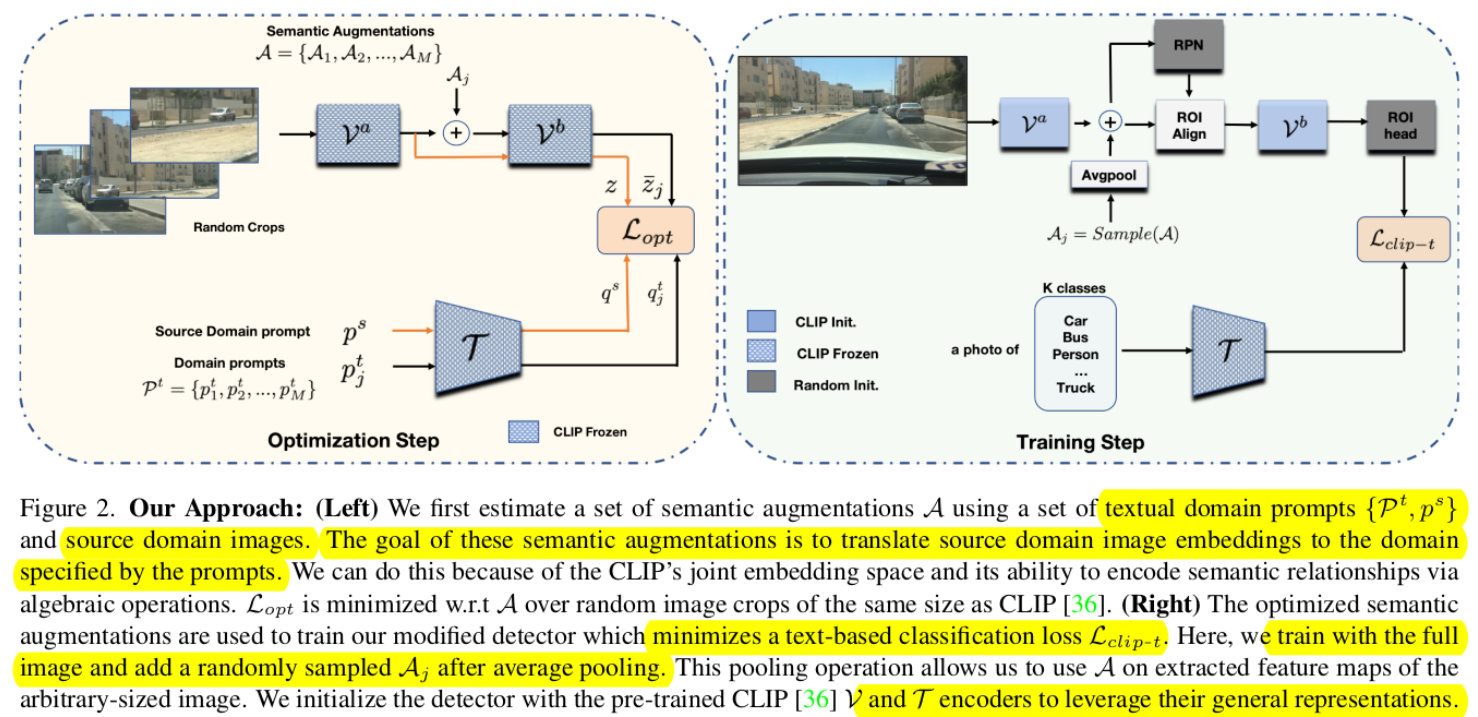
-
Two steps
-
Optimization step
-
Semantic Augmentations (A)를 학습하는 단계. 개인적으로 visual prompt를 학습하는 것으로 사료됨
-
기대하는 바 : visual embedding과 text embedding이 align 되게 학습된 Clip을 활용해서 Source domain 의 이미지 embedding + Source domain의 text embedding 를 Source domain의 이미지 embedding + Target domain text embedding으로 변환해주는 Augmentation (visual prompt $A_j$를 학습)
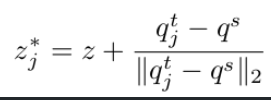
- $q^t_j$ : target domain text embedding (An image of rainy day)
- $q^s$ : source domain text embedding ( An image of sunny day)
- $z$ : cropped image의 visual embedding ($V_b(V_a(I)$)
-
$L_{opt}$
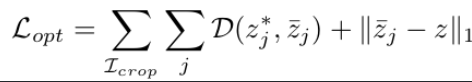
-
$\bar{z}$ = Visual feature에서 visual prompt ($A_j$)를 입력한 Visual embedding
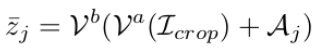
-
D : $\bar{z}$와 $z^*$의 거리
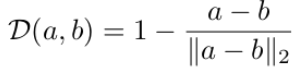
-
-
-
Training step
- 학습된 Visual prompt (A)중에 랜덤하게 추출한 $A_j$를 입력하여 feature 단에서 augmentation 수행
- 임의의 size input image에 대해 dimension을 맞추기 위해 average pooling+channel-wise augmentation을 수행
-
total loss
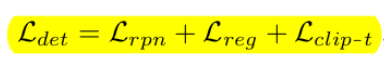
-
clipt-t loss
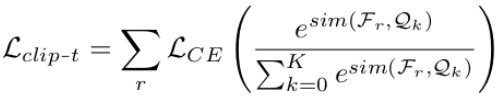
- $Q_k$ : text embedding of each classes (ex. An image of dog, An image of car, etc) (Dim=(K+1) x D_clip)
- k : class index
- $F_r$ : $V_b(RoIAlign(V_a(I)))$. 즉, Clip의 visual Feature + RoIAlign Layer + visual projection head를 통과한 visual embedding (Dim=$D_{clip}$)
- r : RPN layer가 추출한 candidate image region
- $Q_k$ : text embedding of each classes (ex. An image of dog, An image of car, etc) (Dim=(K+1) x D_clip)
-
-