CHARTEDIT: How Far Are MLLMs From Automating Chart Analysis? Evaluating MLLMs’ Capability via Chart Editing
[Chart] CHARTEDIT: How Far Are MLLMs From Automating Chart Analysis? Evaluating MLLMs’ Capability via Chart Editing
- paper: https://arxiv.org/pdf/2505.11935
- github: https://github.com/xxlllz/ChartEdit
- ACL 2025 accepted (인용수: 0회, 2025-05-20 기준)
- downstream task: Chart-to-code generation (Chart editing) task
1. Motivation
-
Rendering 가능한 Chart를 생성하는 일은 labor-intensive하므로, 자동화에 대한 Needs가 있다.
-
기존에 Chart rendering, chart editing task를 MLLM의 능력을 평가하는 benchmark가 부재하다
$\to$ 고품질의 Chart editing 능력을 평가하는 benchmark를 만들어보자!
2. Contribution
- 1,405개의 다양한 editing instruction & 233개의 real-world charts로 구성된 CHARTEDIT benchmark를 제안함
- source: Arxiv에서 crawling
- diversity: 다양성 확보를 위해 19개 chart type & 6개 editing instruction을 사전에 정의함
- 10개의 mainstream MLLM을 두가지 타입의 실험으로 평가하여 결과를 정리함 (code & chart level)
- MLLM의 능력을 평가하기 위한 evaluation metric을 제안 & 평가를 수행함
- execution rate: MLLM이 생성한 code가 실행 가능한가?
- code-level accuracy: 편집의 정확성을 유지하는가?
- chart-level consistency: 시각화된 결과가 정답과 일관되는가?
- 3가지 type의 MLLM에 대해 report (Proprietary, general-domain open-source, chart-domain models) $\to$ GPT-4o가 짱!
- SOTA 모델이 59.96점을 맞고 있음을 밝히며, 해당 task처럼 정밀한 코드 수정이 어려운 task임을 보임
- MLLM의 능력을 평가하기 위한 evaluation metric을 제안 & 평가를 수행함
3. Related Works
3.1 Chart-Domain MLLMs
- ChartLlama: LLaVA기반 Chart dataset으로 finetuned.
- mPLUG-Owl / mPLUG-Owl2: 고해상도 chart image에서 좋은 성능
- ChartVLM: LLM의 개입이 필요한지 여부를 판단하는 discriminator를 도입
- TinyChart: token merging + PoT-based reasoning 전략을 통해 inference 효율성 & 이해력 향상
- ChartMoE: MoE 구조를 채택
3.2 MLLMs for Code
- Deepseek-coder : code generation & error fixing 능력의 진전을 보임. (text-only)
- sign2Code / Web2Code: webpage용 HTML code 생성
- RoboCodeX: robot behavior synthesis하는 code 생성
- ChartMimic/ChartVLM: Chart-to-code generation task를 수행했으나, 1가지 타입의 modification만 수행하여 다양성 부족
4. ChartEdit
-
Overall pipeline
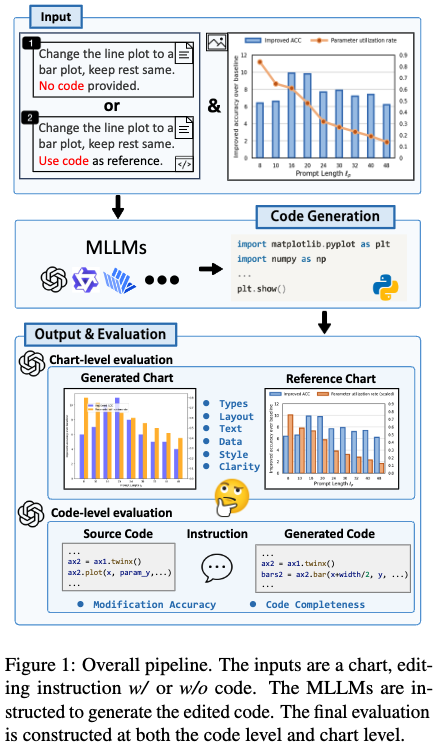
4.1 Chart Editing Task Definition
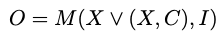
- M: MLLM 모델
- X: Chart 이미지 (from Archiv papers)
- C: 해당 Chart 이미지와 연관된 code
- I: 편집을 어떻게 수행해야 하는지 정의한 instruction
- O: 모델이 생성한 code. 해당 코드를 돌리면 chart가 랜더링 되어야 한다.
4.2 Data Construction
- Crawling Tool: BeautifulSoup 사용
4.2.1 Chart Collection & Filtering
-
수집된 arciv paper중, “accept”, “under review”, “camera ready”, “submit” keyword가 있는 경우, filtering
-
ArXiv API 활용하여 LaTeX source file 추출
-
Chart와 유관해 보이는 이미지 파일 외 무관한 source file은 제거 (.png, .pdf, .jpg, .svg만 남김)
-
2 Step으로 고품질 chart 이미지만 남김
-
MLLM을 통해 해당 이미지가 chart인지 평가하도록 함 (zero-shot prompting) $\to$ 저품질(?) chart가 여전히 잔존함.
- InternVL2.5-78B 사용
-
MLLM-as-a-judge로 품질에 대해 scoring하는 매커니즘 도입
-
Aesthetics
-
Readability
-
Reproducibility
-
Data Presentation Simplicity
$\to$ 평균 90/100점 이상만 추출. 최종 1,000개의 고품질 chart image만 추출
-
-
4.2.2 Code Annotation
-
고품질 chart image에 대응하는 code가 없으므로, manually python 코드를 작성함
-
여전히 부족한 chart type의 경우, Kaggle과 Matplotlib gallery에서 추가함.
-
Data leakage를 고려해, 수동으로 해당 코드를 수정함
$\to$ 233개의 chart + code paired data를 구축
-
4.2.3 Instruction Generation
-
2가지 타입의 instruction을 제안
-
LLM-based: 5가지 편집 카테고리를 사전 정의함. Multiple subtype로 구성.
- style
- format
- layout
- data
- text
$\to$ image + code를 입력으로 주면서, 해당 code를 editing할 instruction을 반환.
$\to$ 다양한 출력과 error 최소화를 위해 최소한 3개의 variation을 생성하도록 명령함.
$\to$ human expectation과 정렬하기 위해 해당 instruction과 edited image의 결과를 수동으로 모니터링 함.
$\to$ 1,172개의 <chart, instruction, code> triplet paired dataset 완성
-
human-written
- LLM-based dataset이 LLM output으로 인한 다양성에 한계가 있어, chart별로 human이 1개씩 editing instruction을 추가함
$\to$ 1,405개의 <chart, instruction, code> triplet paired dataset 완성
-
4.3 Dataset Statistics & Analysis
-
Instruction dataset 분석
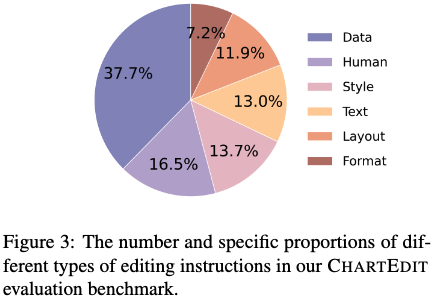
-
Chart의 분포
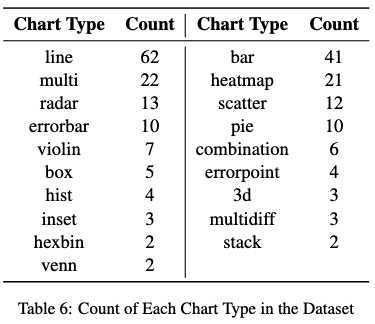
-
Instruction text의 Sentence-BERT 기반 embedding 분포
5. Experiments
-
평가대상
- Proprietary Models
- GPT4-o, Claude-3.5-Sonnet
- OpenSource General-Domain Models
- InternVL-V2.5-78B, Qwen2-VL-72B, LLaVA, Phi-3.5-Vision
- Chart-Domain Models
- ChartLlama, TinyChart, ChartMoE
- Proprietary Models
-
평가 방법
-
LLM-as-a-Judge를 활용 (GPT-4o)
-
생성된 코드가 instruction과 정렬이 되었는가? (code-level)

- Modification Accuracy
- Code Completeness
-
의도한 chart를 효과적으로 생성하였는가? (chart-level)

- Chart generation 능력
-
-
-
정량적 결과
-
Overall
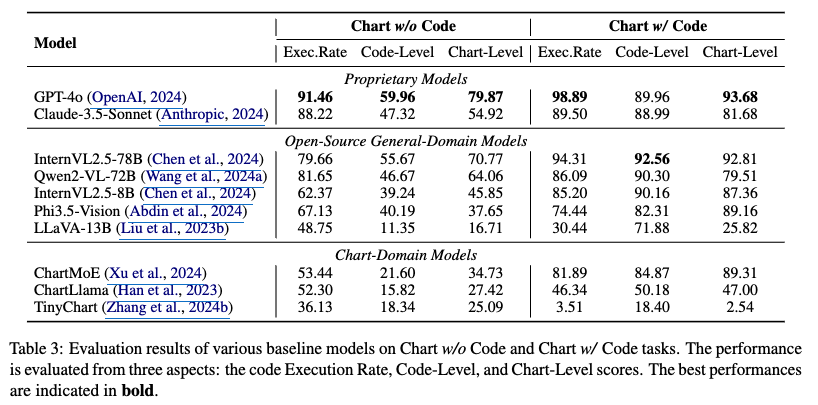
-
w/o code 구체적인 결과
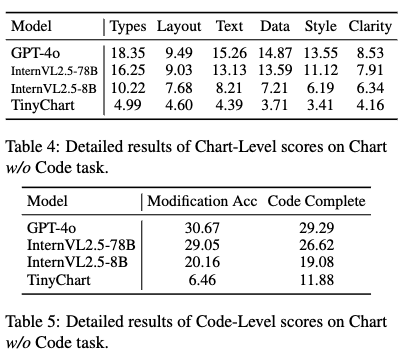
-
-
정성적 결과
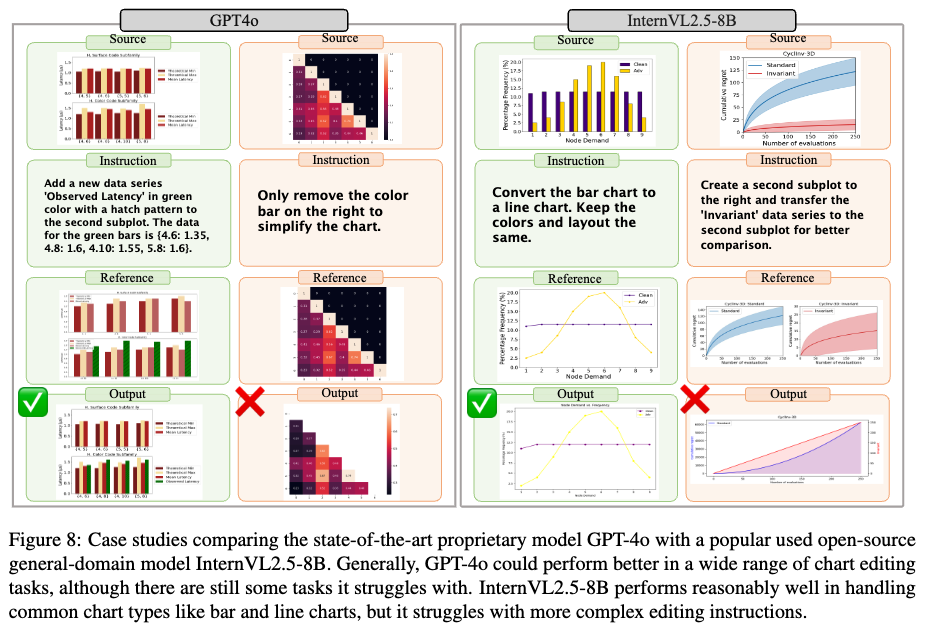
-
Discussion
-
CoT prompting vs. Plain prompting
-
성능 향상이 없음 (비슷)
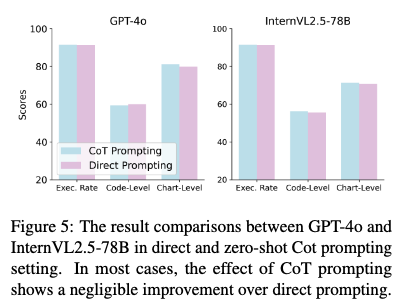
-
Code generation prompt

-
-
Editing instruction 타입별로 MLLM의 성능이 어떻게 되는가?
-
code-level: chart type (format) 변경에 제일 우수한 성능을 보임
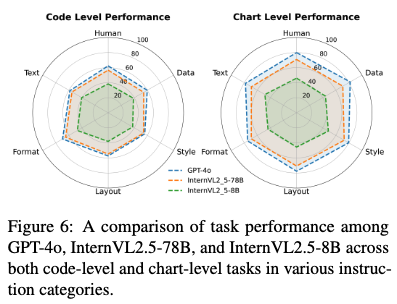
-
chart-level에서 format의 성능이 뛰어나진 않음 $\to$ 빼먹는 정보가 존재
-
-
Chart의 타입별 MLLM의 성능이 어떻게 되는가?
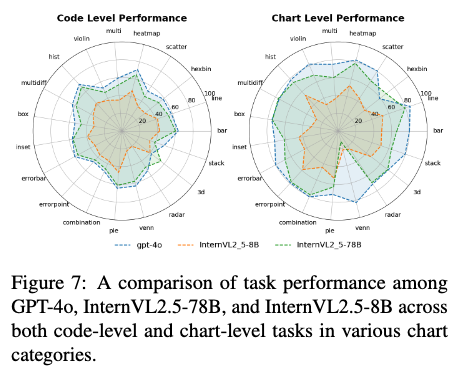
- venn diagram에서 proprietary vs. opensource model의 성능 격차가 제일 크게 존재함
- errorbar, multi chart와 같이 복잡한 chart에서도 그러함
- code-level task에서 InterVL2.5-7B vs. GPT-4o가 유사한 성능 내는 주요 원인이 instruction following 능력때문임을 발견함
-
Error 유형이 어떻게 되는가?
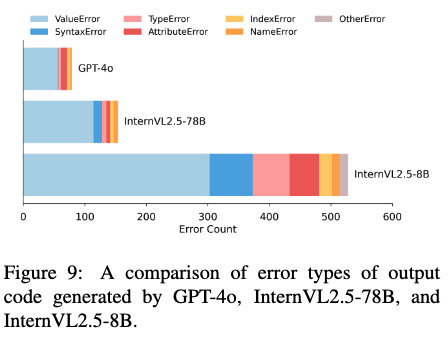
- ValueError가 제일 크다. (50% 이상)
-