[UDA][CLS] CDTrans: Cross-domain Transformer for Unsupervised Domain Adaptation
[UDA][\CLS] CDTrans: Cross-domain Transformer for Unsupervised Domain Adaptation
-
‘22.3.19 ICLR 2022 accept
-
인용수 : 60회
-
UDA Classification task SOTA
- VisDa-2017 (5등)

- DomainNet (2등)

-
github: https://github.com/CDTrans/CDTrans
-
paper : https://arxiv.org/abs/2109.06165
Abstract
- 기존 UDA의 한계점
- Task : Classification
- CNN기반 모델은 Noisy Pseudo label 생산한다. → 최근 성능이 좋은 Transformer로 변경한다.
- 트랜스포머 관련 자료 : https://gaussian37.github.io/dl-concept-vit/
- 제안하는 방식
- pseudo labeling : two-way center-aware labeling algorithm
- model architecture : weight-sharing triple-branch transformer framework
- self-attention : source/target feature learning
- cross-attention : source/target domain alignment
1. Introduction
- Model architecture
- Transformer의 cross-attention → Noisy Pseudo label의 noise를 효과적으로 완화함
- 2-branches : source, target domain specific한 feature학습
- 1-branch : source & target domain의 feature alignment
- Transformer의 cross-attention → Noisy Pseudo label의 noise를 효과적으로 완화함
- Pseudo labeling
- two-way center aware labeling method → pseudo label의 quality를 향상
2. Related Work
Transformers for Vision
- NLP분야에서 처음 사용됨
- ViT (2020) : image를 patch단위로 쪼개어 학습함
- DeiT (2021) : KD방식을 ViT에 적용함
- 여러 Vision downstream task에 활용됨
- Classification
- Object Detection
- Person Re-ID
- Multi-modal task에서 사용됨
Unsupervised Domain Adaptation
- domain-level : domain-alignment로 source, target domain간의 divergence를 줄임
- Maximum Mean Discrepancy (MMD) (2006)
- Correlation Alignment (CORAL) (2016)
- category-level
- fine-grained category alignment를 통해 classwise alignment 수행 (2018) (2021)
Pseudo Labeling
- Labeled data와 함께 Pseudo label을 fine-tuning에 활용
- conditional distribution alignment (2017)
- Regularization으로 활용 (2018)
- self-training 사용 (2018)
- k-means clustering기반 self-supervised method (2018)
- noisy peudo label을 효과적으로 줄이는 self-supervised 방식 (2020) → base 논문
3. Approach
3.1 The Cross Attentions in Transformer
-
Self-attention module
-
came from ViT (Vaswani et al., 2017)
\[Attn_{self}(Q, K, V)=softmax(\frac{QK^T}{\sqrt{d_k}})V\]- $Q$, $K$: $\inR^{N \times d_k}$, Query and Key, respectively.
- 물리적 의미: patch간의 similarity. Value의 Weight 활용
- $V\in R^{N \times d_v}$, Value
- $N$: patch의 갯수. $I \in x^{H \times W \times C} =x^{N \times (P^2 C)}$일때, $N=\frac{HW}{P^2}$
- $P$: Patch의 크기
- $Q$, $K$: $\inR^{N \times d_k}$, Query and Key, respectively.
-
-
Cross-attention module
-
Self-attention module과 다르게 $I_s, I_t$ 을 입력으로 받음
\[Attn_{self}(Q_s, K_t, V_t)=softmax(\frac{Q_sK_t^T}{\sqrt{d_k}})V_t\]- $Q_s$, $K_t$: $\inR^{M \times d_k}$, Query and Key, respectively.
- 물리적 의미: Source patch& Target patch간의 similarity. Value의 Weight 활용
- $V_t\in R^{N \times d_v}$, Value
- M: patch의 갯수. $I \in x^{H \times W \times C} =x^{M \times (P^2 C)}$일때, $M=\frac{HW}{P^2}$
- $P$: Patch의 크기
- $Q_s$, $K_t$: $\inR^{M \times d_k}$, Query and Key, respectively.
-
-
Cross-Attention Module의 유무에 따른 성능 변화
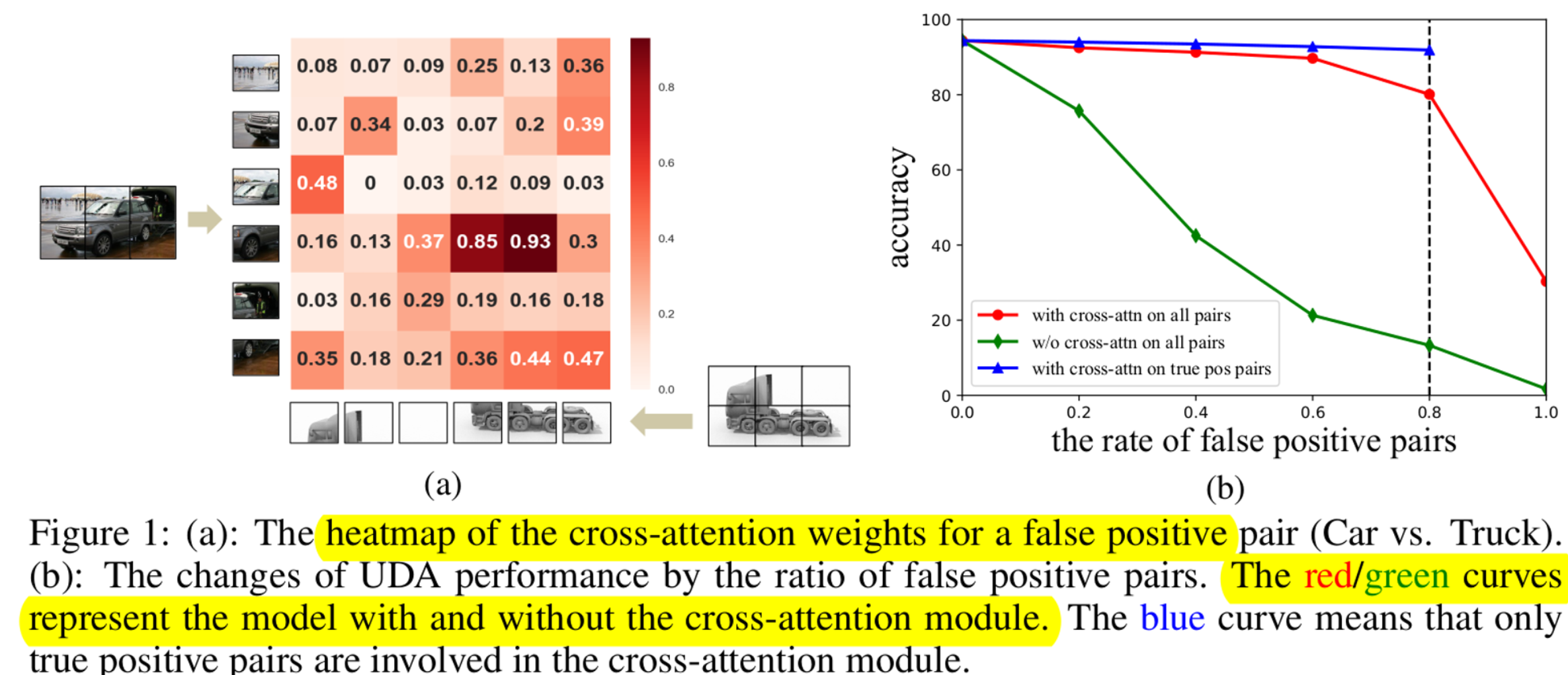
- False positive source, target image patch 간의 dissimilar하게 되므로 noise label을 filtering함
- 반면, true positive patch간의 similar, dissimilar 여부는 성능 하락에 지장을 안주므로 고려 안함
3.2 Two-way Center-aware Labeling Method
Two-way Labeling
- Cross-attention module에 사용할 Source & Target 유사도가 높은 이미지 추출
-
$P_s={(s,t) s=min_k d(f_s, f_k), \forall k \in T, \forall s \in S}$ - $f$: feature of each domain
-
$P_t={(s,t) t=min_k d(f_s, f_k), \forall k \in T, \forall s \in S}$ - $P={P_s \cup P_t}$
-
Center-aware Filtering
- Source-only pretrained model로 classwise probability distribution의 mean값을 계산함
- k-mean clustering algorithm으로 class index 할당
- k-mean cluster결과와 pseudo label의 결과가 같으면 학습에 활용. Vice versa
3.3 Cross-domain Transformer (CDTrans)
-
3 branches
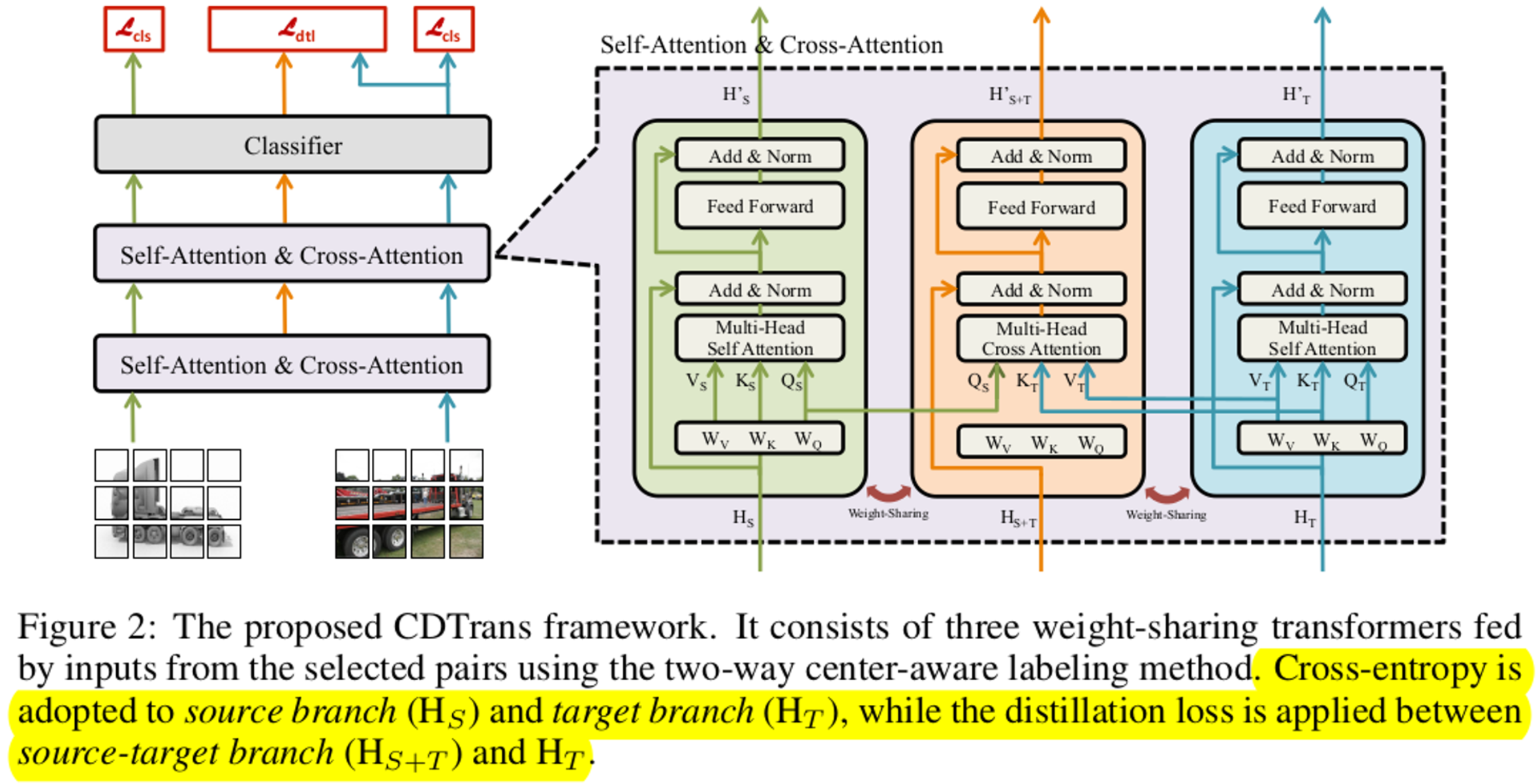
- Source branch : Self-attention layer로 Source domain specific feature를 학습
- Target branch : Self-attention layer로 Target domain specific feature를 학습
- Source&Target branch : Cross-attention layer로 S&T domain feature alignment
-
Loss
- Cross-entropy Loss
- Source branch
- Target branch
- Distillation Loss
- Teacher : Source&Target branch output
- Student : Target branch output
- Used in inference
- Cross-entropy Loss
4. Experiments
Dataset
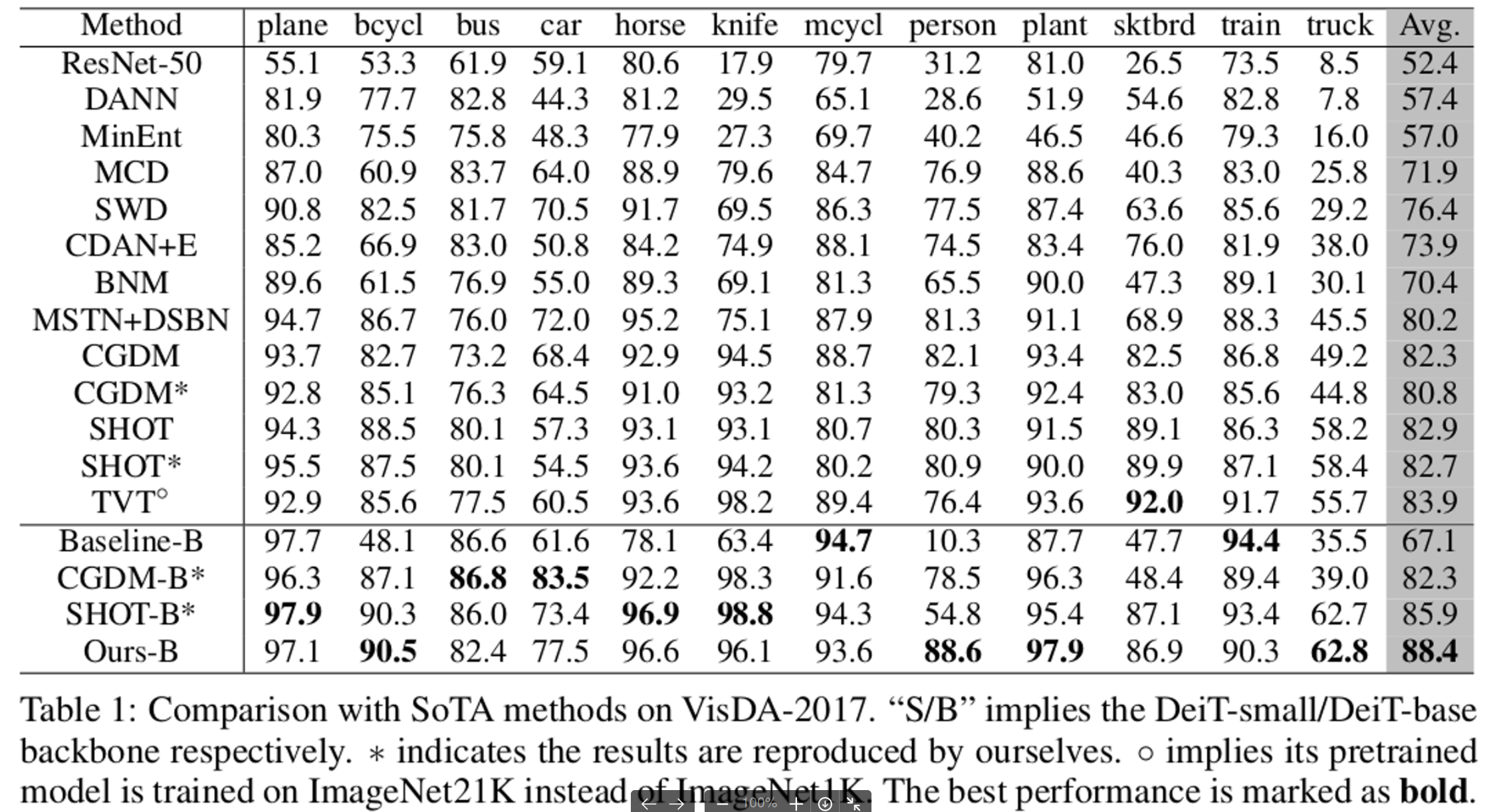
- VisDA-2017
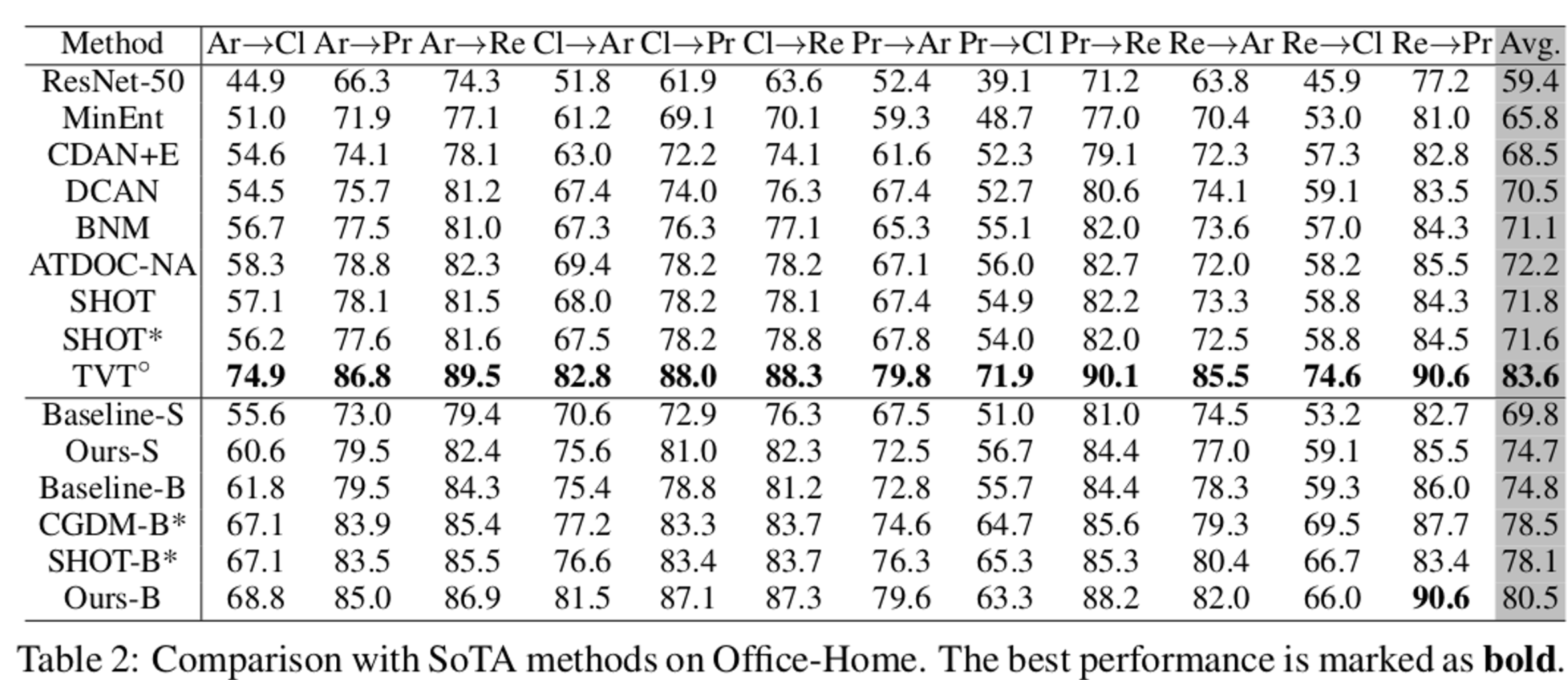
- Office-Home
-
Office-31
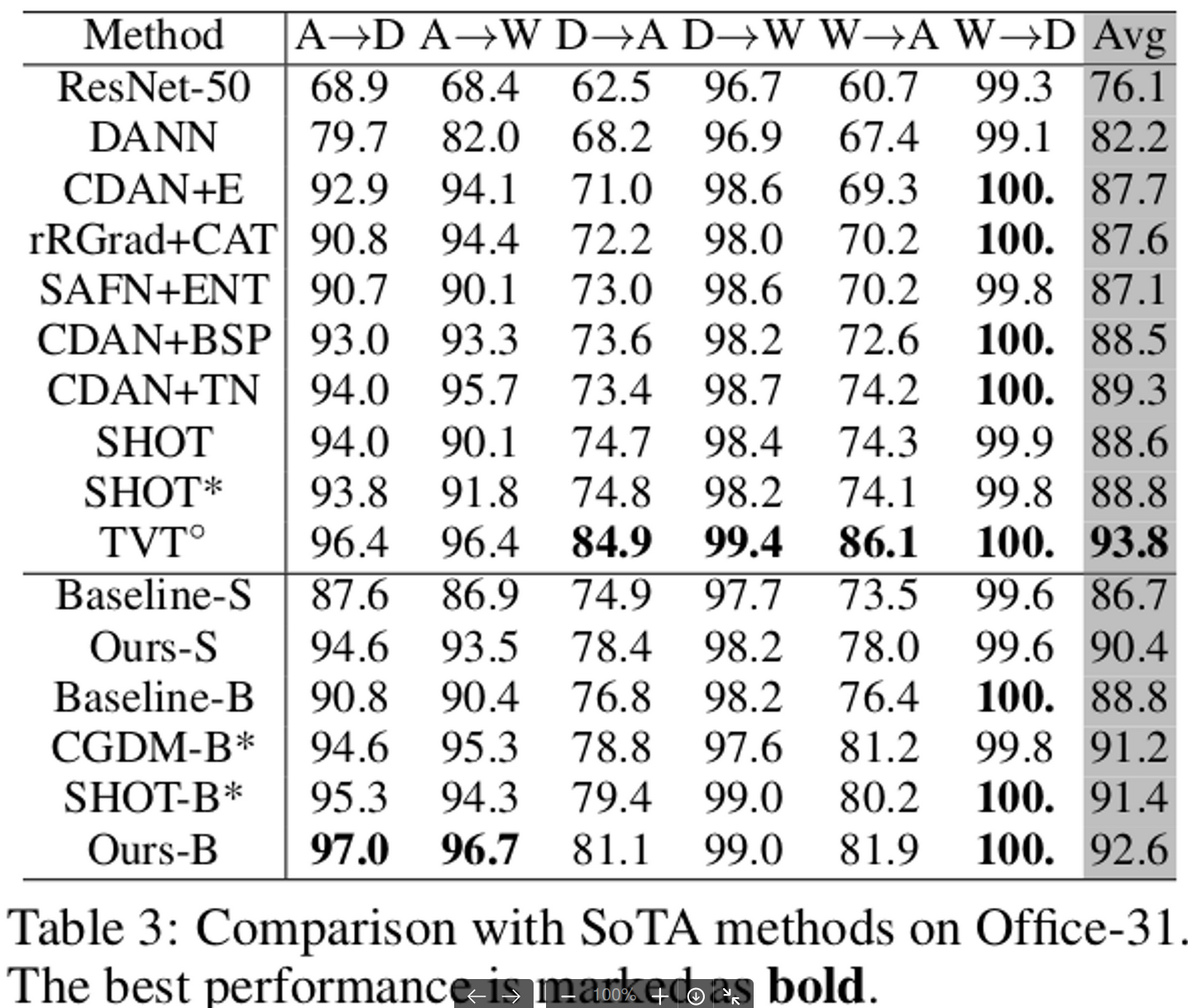
- TVT는 ImageNet21K pretrained ViT를 사용했기에 성능이 더 좋음
- CDTrans는 ImageNet1K pretrained DeiT사용
-
DomainNet
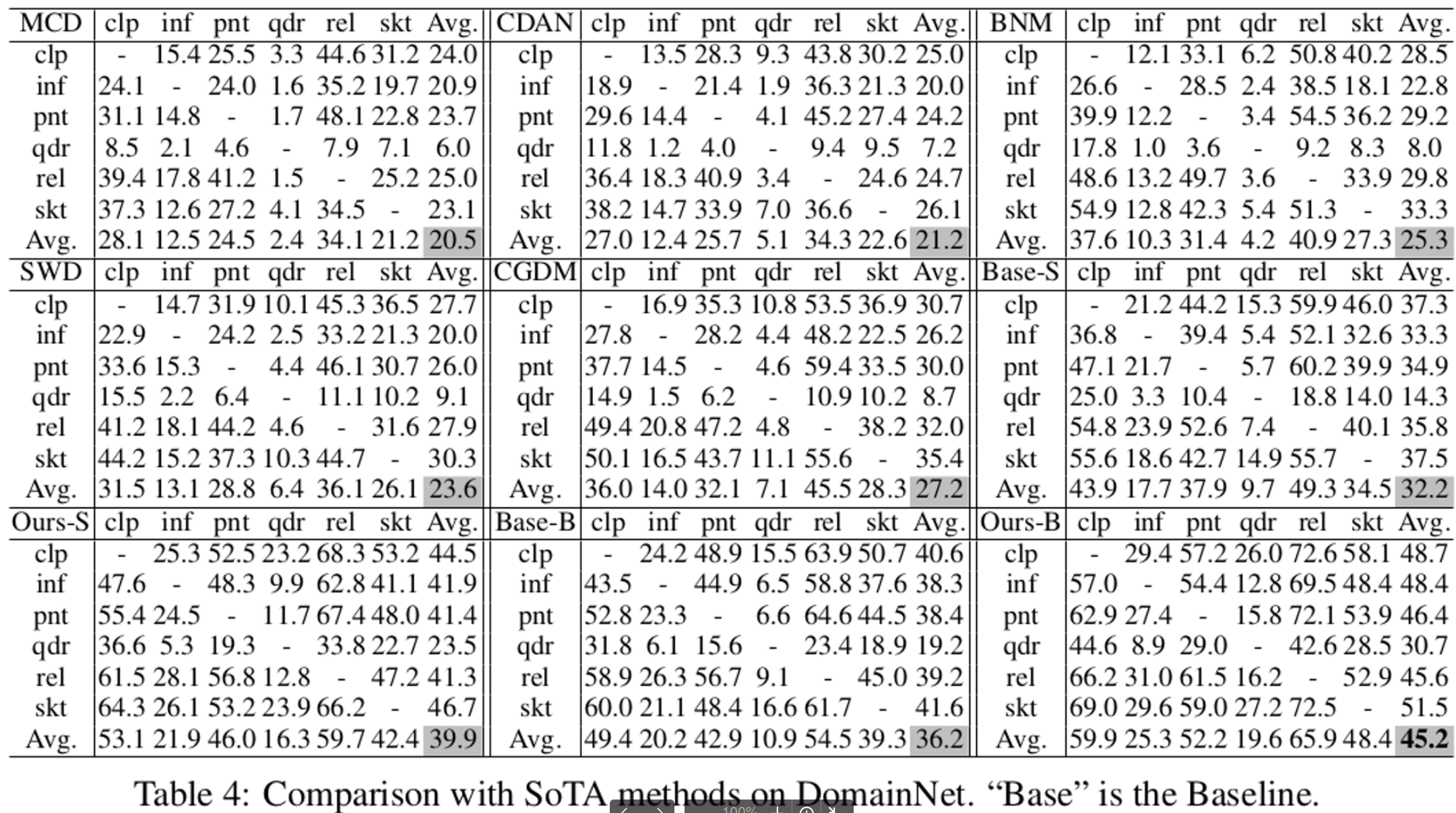
- SOTA를 넘음
Model
- DeiT-small, DeiT-base (2021)
Ablations
- Two-way Center aware pseudo labeling

-
Loss
- cls loss 보다 distillation loss가 낫다 (row 3 vs row 4)
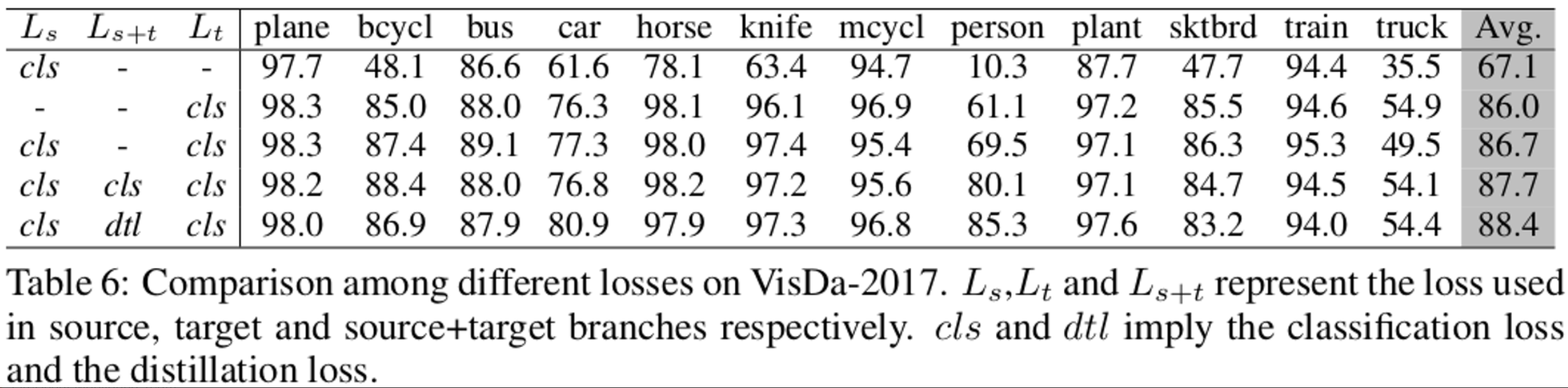
- Pseudo label 사용한 게 안한것보다 낫다 (row 1,2 vs row 3)
5. Conclusion
- two-way center-aware pseudo labeling 제안했다
- Transformer기반 cross-attention module을 제안했다
- UDA 4개의 classification task에서 SoTA를 찍었다