[SSL][CLS] CCSSL: Class-Aware Contrastive Semi-Supervised Learning
[SSL][CLS] CCSSL: Class-Aware Contrastive Semi-Supervised Learning
- paper: 69회
- github: https://github.com/TencentYoutuResearch/Classification-SemiCLS
- CVPR 2022 accepted (인용수: 69회, ‘24-01-09 기준)
- downstream task: SSL for (noisy) CLS
1. Motivation
-
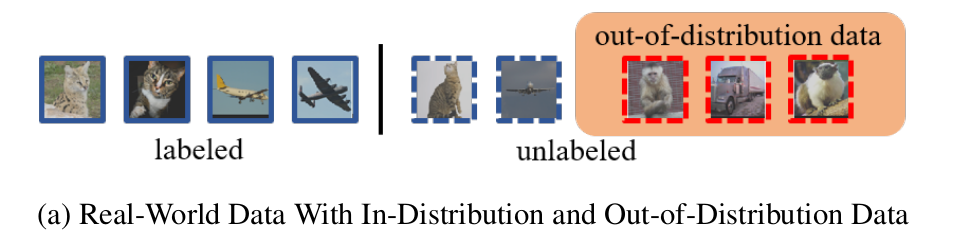
unbalanced, out-of-distribution data가 공존하는 unlabeled data를 가정한 real-world data에서 SSL for classification 성능을 높여보자!
2. Contribution
-
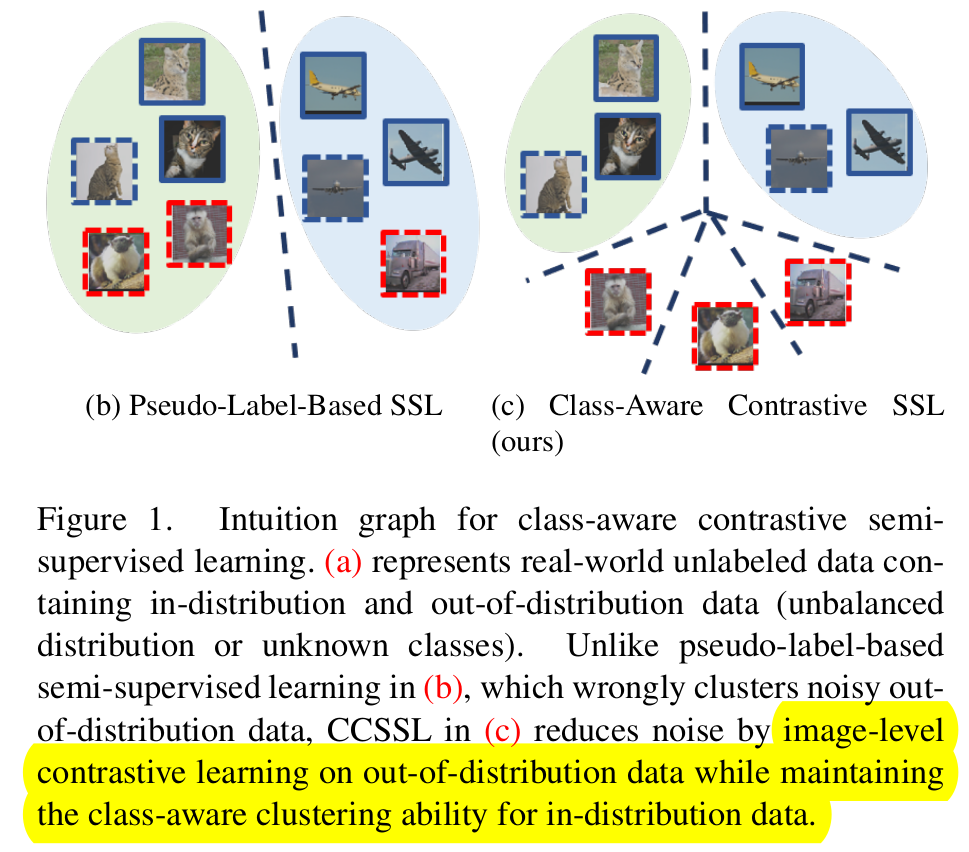
In-distribution은 class-wise contrastive (pull) & out-of-distribution은 image-wise contrastive (push)로 학습하는 CCSSL (Class-aware Contrastive Semi-Supervised Learning)을 제안함
-
Target-reweighting을 통해 noisy label에 대한 implicit noise를 제거함
-
다른 SOTA SSL과 비교하여 성능 향상을 보임
3. CCSSL
-
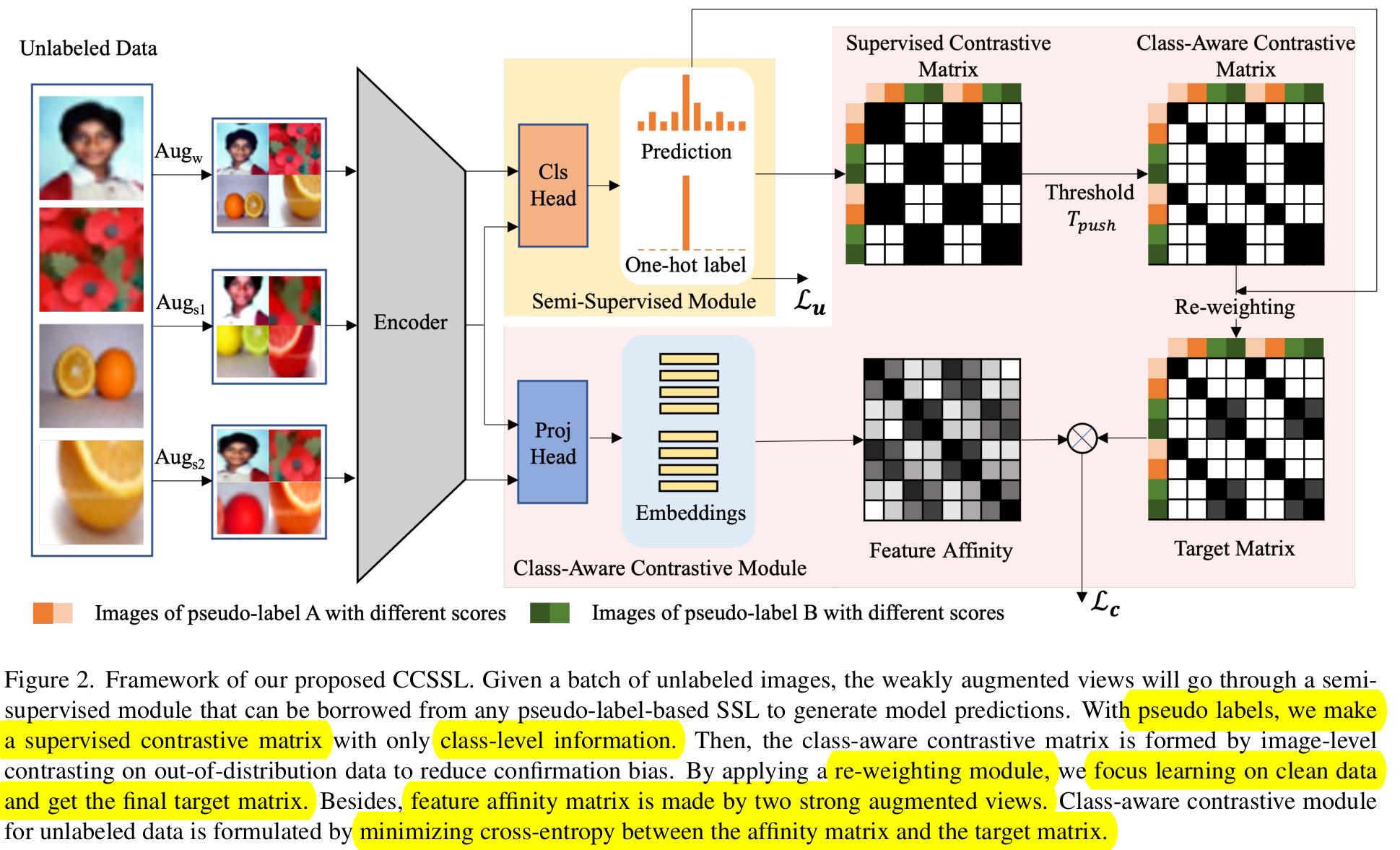
Framework
-
Encoder $r=F(Aug(x))$
-
Semi-supervised module : FixMatch 사용
-
Class-Aware contrastive module
- In-distirbution : pusedo label의 confidence가 threshold $T_{thres}$보다 큰 경우. 같은 class image 간에 pull하도록 contrastive learning (class-wise)
- Out-of-distribution : pseudo label의 confidence가 threshold $T_{thres}$보다 작은 경우. 자기 자신의 이미지만 pull하고, 나머진 push하도록 consrastive learning (image-wise) $\to$ 기존의 contrastive learning과 동일
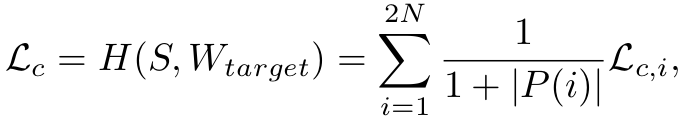
-
$P(i)$ : i번째 sample과 positive pair를 이루는 집합의 갯수. mini-batch 단위로 계산 -
$W_{target}$: contrastive matrix $\in \mathbb{R}^{2N \times 2N}$
-
in distirbution 일 경우
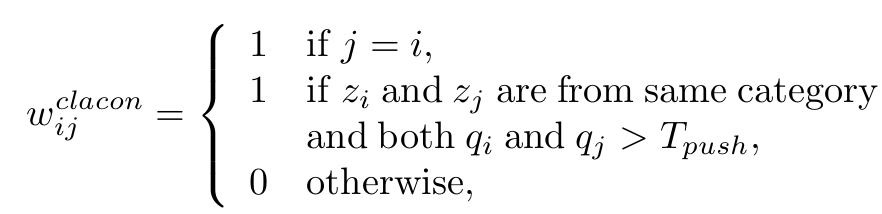
-
out-of-distribution 일 경우
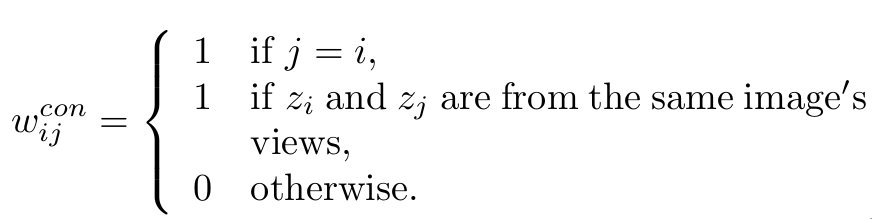
-
-
Foreground Re-weighting
-
Class-aware contrastive module을 통과하더라도, $p > T_{push}$인 경우에도 noise label이 있을 수 있다. 이를 완화 하기 위해 contrastive matrix에 probability score로 weight를 준다. (?)
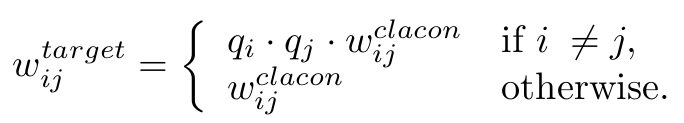
-
-
-
최종 식
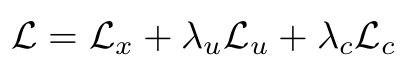
4. Experiments
-
CIFAR-10/CIFAR-100/STL-10
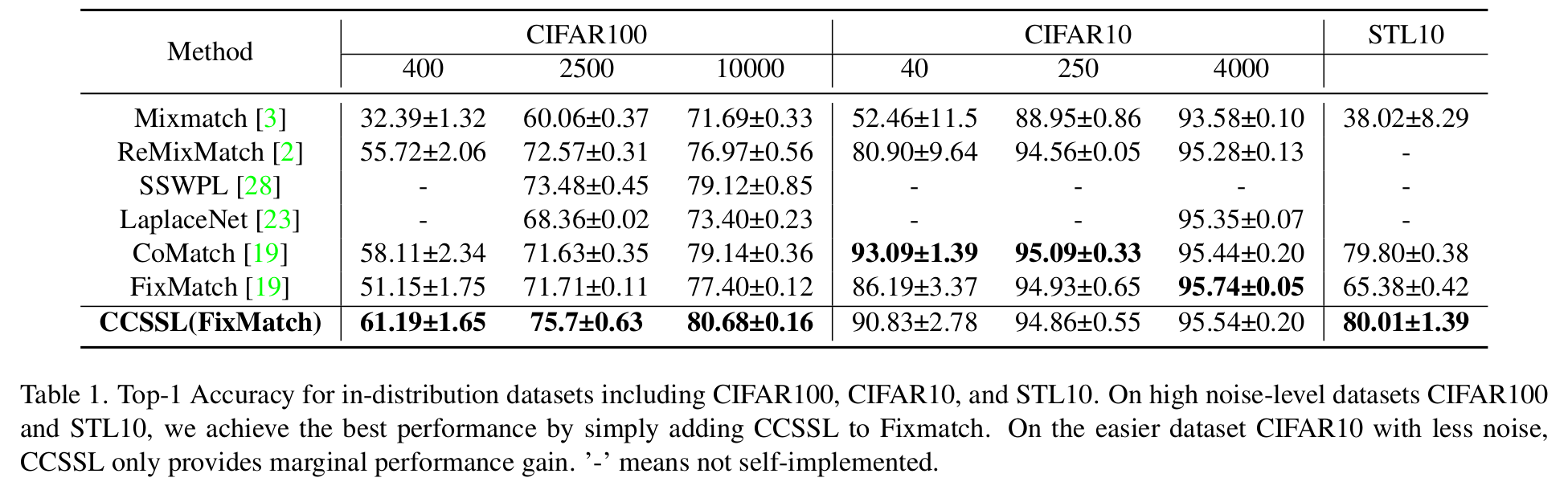
- 4-shot/25-shot/40-shot learning
-
Semi-iNat 2021 (noisy dataset)
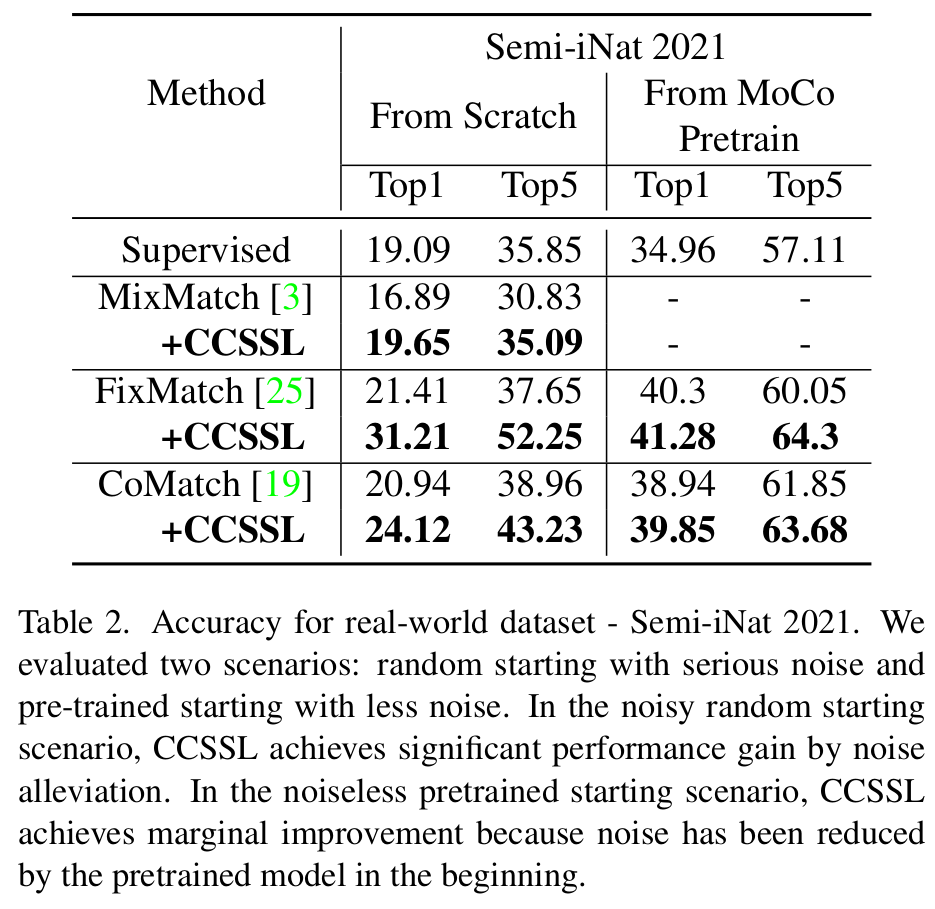
- 더 noisy한 데이터셋에서 CCSSL의 성능이 더욱 크게 향상된다.
-
Convergence graph
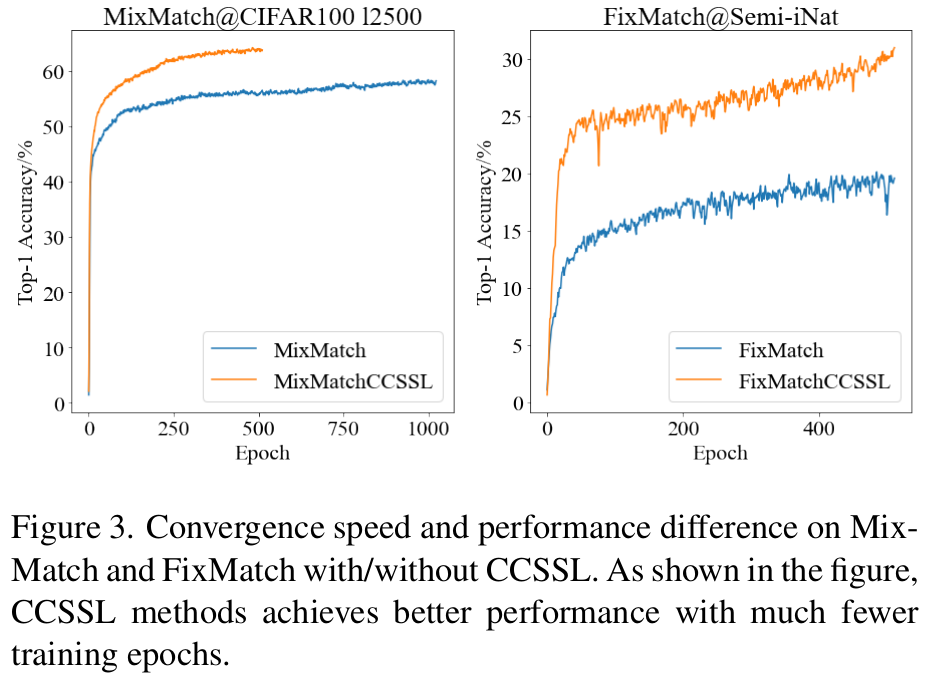
- SubCon. Loss가 학습 속도를 빠르게 수렴시킨다.
-
Ablation Study
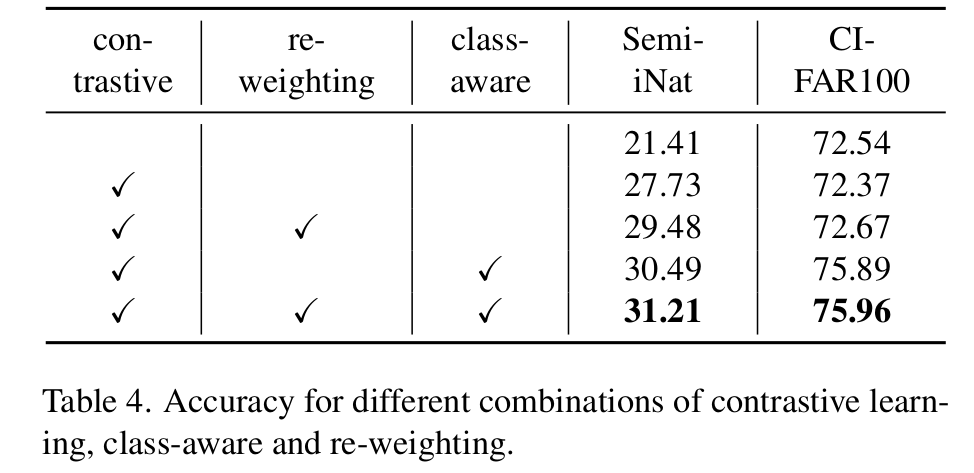
-
Grad-CAM

-
unlabel vs. label 비율 $\mu$에 따른 ablation. 클수록 unlabel의 비중이 증가
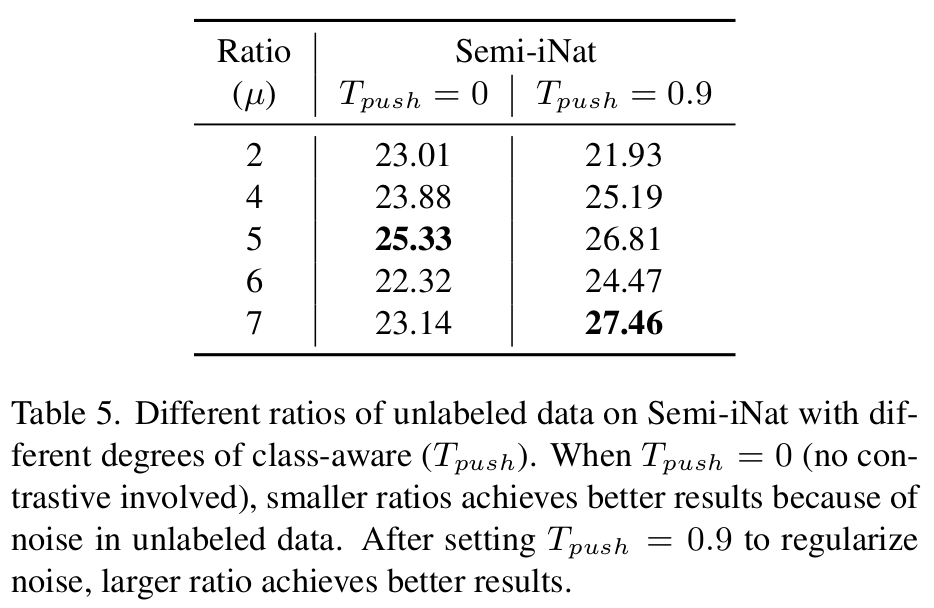
- $T_{push}=0$: 동일 class면 모두 pull하다 보니 noisy label이 많아 unlabel data 비율이 많아지면 오히려 성능 하락 발생함
- $T_{push}=0.9$: 동일 class 내 p>0.9만 pull하다 보니 많아 unlabel data 비율이 많아지면 성능이 증가함
-
$T_{push}$ 의 따른 ablation
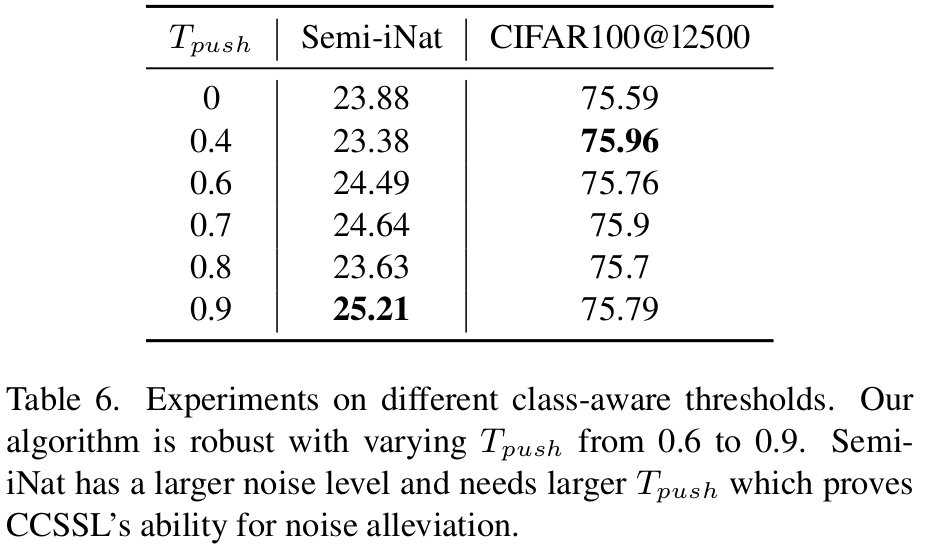
- Semi-iNat과 같이 noisy level이 높은 data는 threshold = 0.9에서 최적
- CIFAR100처럼 easy level인 dataset은 threshold = 0.4에서 최적
-