[OD][CLS] CBAM: Convolutional Block Attention Module
[OD][CLS] CBAM: Convolutional Block Attention Module
- paper: https://arxiv.org/pdf/1807.06521.pdf
- github: https://github.com/Jongchan/attention-module
- ECCV 2018 accepted (인용수: 15,729회, ‘24-01-07 기준)
- downstream task: OD, CLS
1. Contribution
-
CNN 구조를 지닌 모델의 CNN의 feature enhancement를 시켜주는 CBAM (Convolutional Block Attention Module)을 제안함
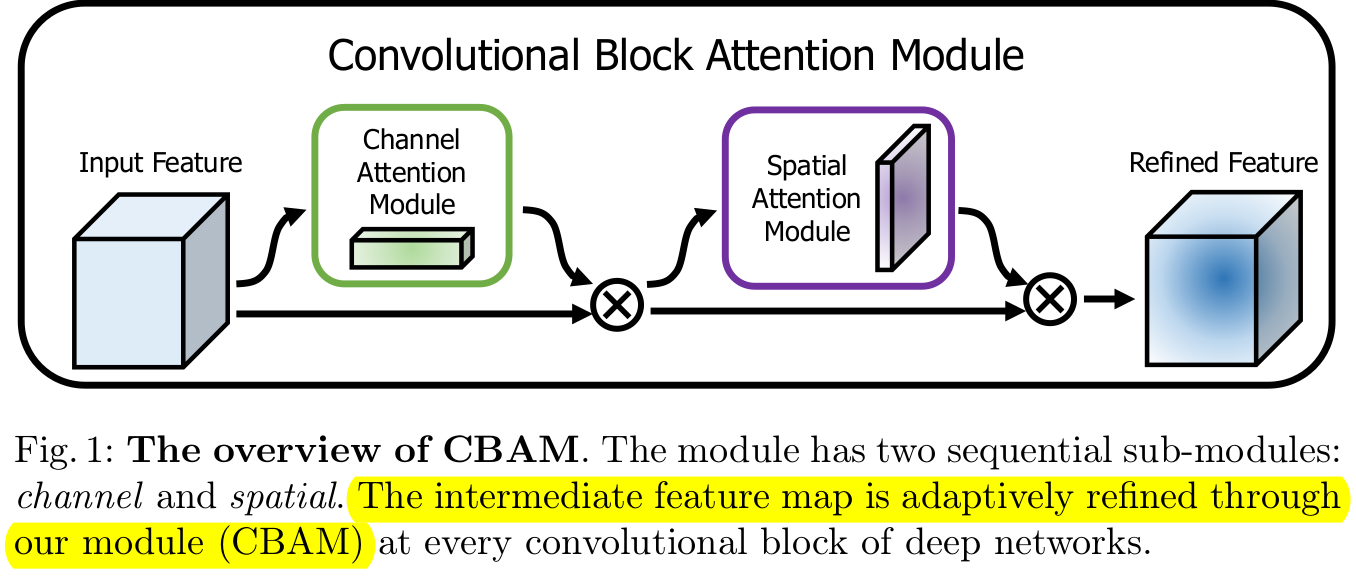
- Spatial Attention & Channel Attention 2개의 separate dimension으로 attention을 수행하는 light-weight attention module
-
Ablation Study를 통해 Attention module의 효과를 입증함
- attention해야 할 위치만 알려줄 뿐만 아니라, element-wise multiplication을 통해 representation을 stronger하게 만듦
- 추가되는 parameter 와 complexity는 무시 가능함
- OD, CLS dataset들에서 성능 향상을 보임
2. CBAM
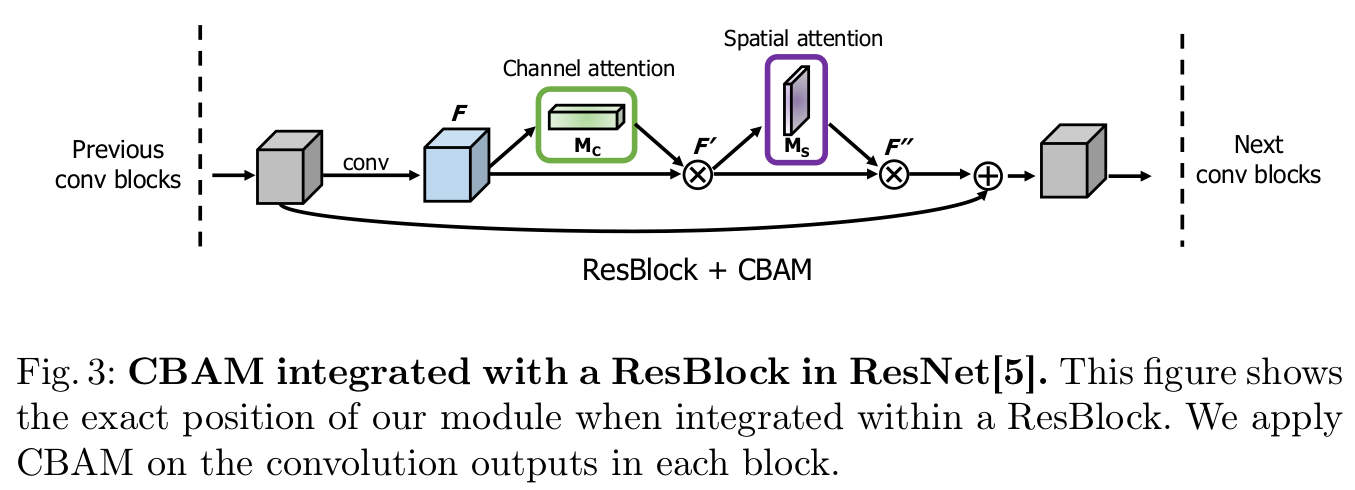
-
Feature Map F $\in \mathbb{R}^{C \times H \times W}$
-
1D channel attention map M$_c \in \mathbb{R}^{C \times 1 \times 1}$
-
2D spatial attention map M$_s \in \mathbb{R}^{1 \times H \times W}$
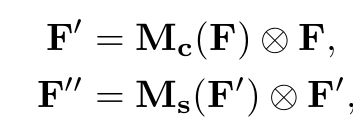
- 각 attention map은 해당 dimension으로 broadcase됨
-
2.1. Channel Attention
-
이미지 내에서 channel dimension으로 globally ‘무엇을(what)’ focus해야 하는지 알려주는 attention module
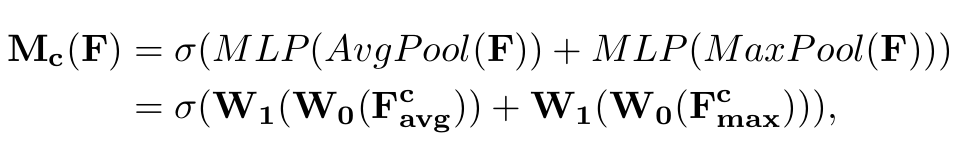
-
Max pooling과 Average pooling operator를 통해 (global한) spatial information을 획득함
-
Shared MLP를 통해 획득된 spatial 정보를 한번 encoding을 수행함
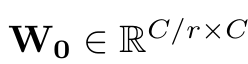
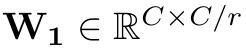
- r: channel reduction ratio (r=16 사용)
-
2.2. Spatial Attention
-
이미지 내에서 spatial dimension (HxW)으로 locally ‘어디를(where)’ focus해야 하는지 알려주는 attention module
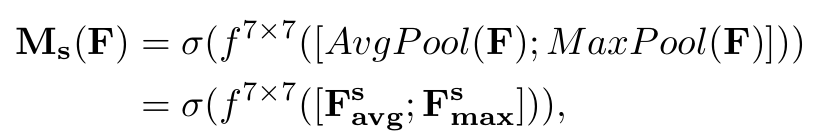
-
Max pooling과 Average pooling을 통해 (locally한) channel information을 획득함
-
7x7 conv. layer를 통과하여 encoding을 수행함
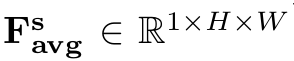
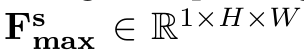
-
3. Experiments
-
Channel Attention
-
Max pooling & Average pooling 사용 유무에 따른 성능 분석
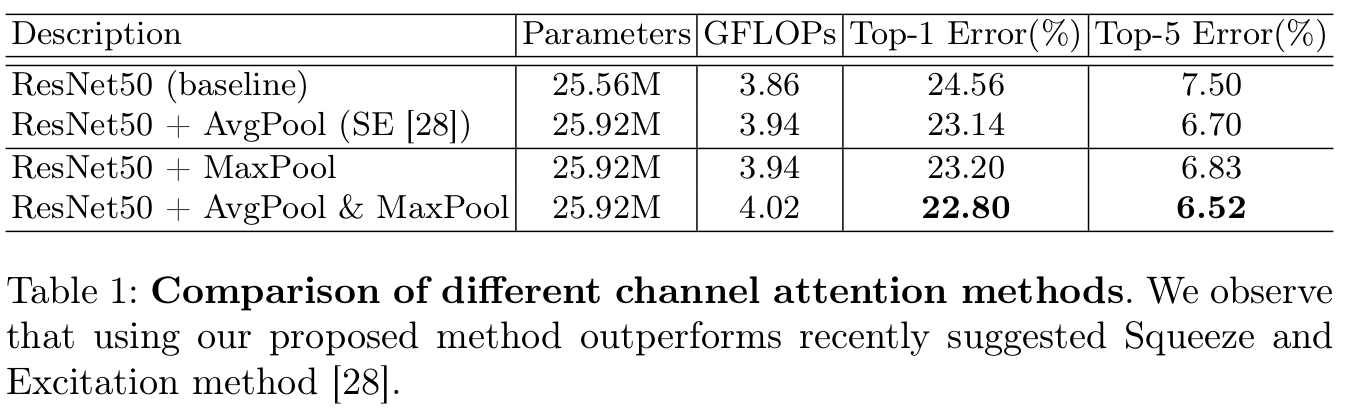
-
max pooling : 제일 salient한 part에 대한 정보를 encoding
-
average pooling : global statistically feature를 softly encoding
$\to$ 둘 다 사용하는 것이 성능 향상에 제일 좋았음
-
-
-
Spatial Attention
-
maxpool + avgpool / 1x1 conv 과 kernel size에 따른 성능 분석
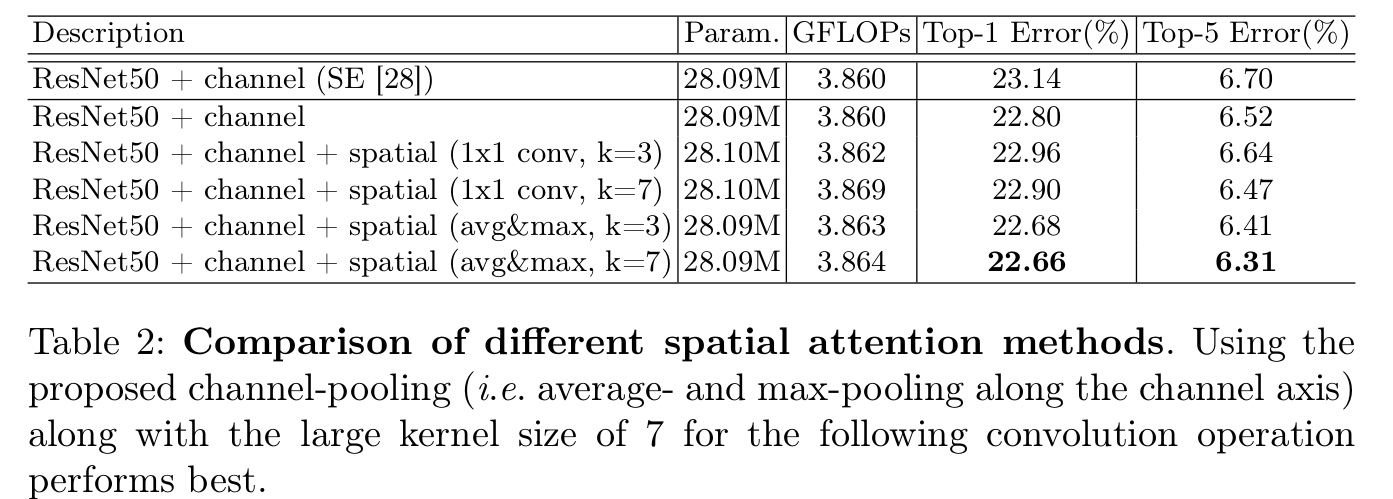
- spatial 정보 aggregate할 때 learnable (1x1 conv)보다 explicit하게 modeling된 pooling feature가 더 좋았음
- kernel size가 3보다 7이 더 좋았음. 이는 더 넓은 영역을 attention에 사용하는 것이 좋다는 것을 의미함
-
-
Channel attention & Spatial attention module을 어떻게 arrange하는가에 따른 성능 분석
-
sequential channel-spatial, sequential spatial-channel, parallelly로 비교함
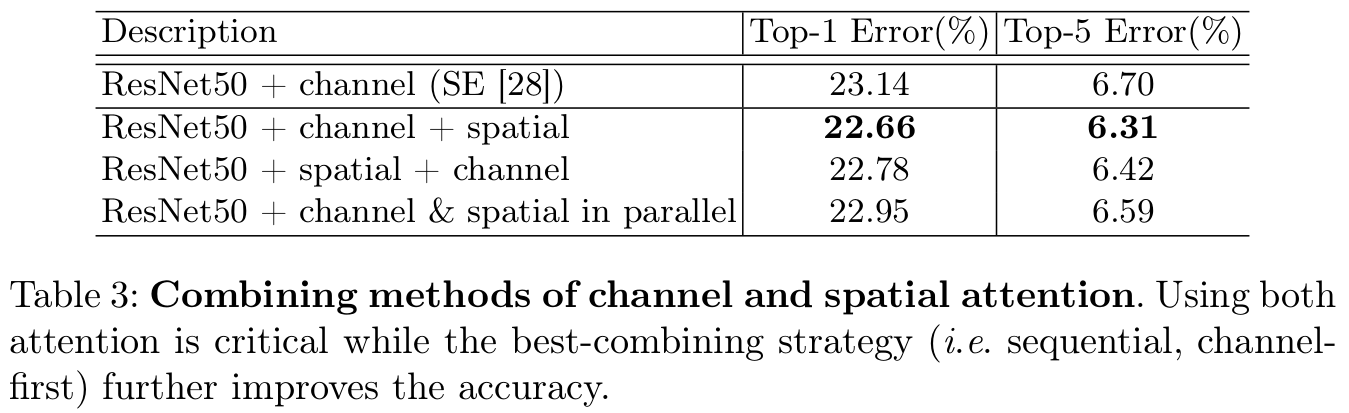
- sequential channel + spatial이 제일 좋았음
-
-
ImageNet-1K classification 결과
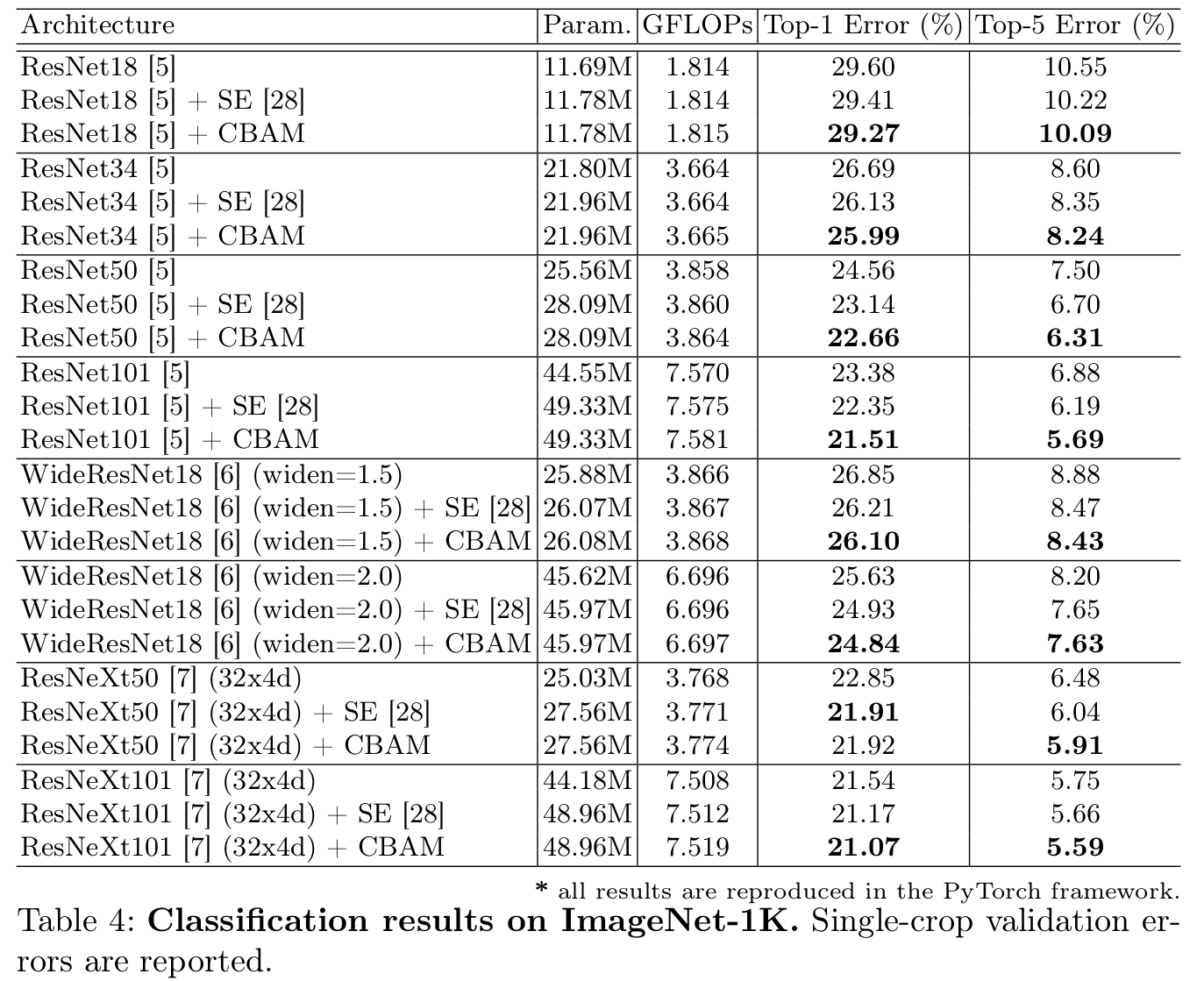
-
edge-device용 backbone 성능 결과 분석
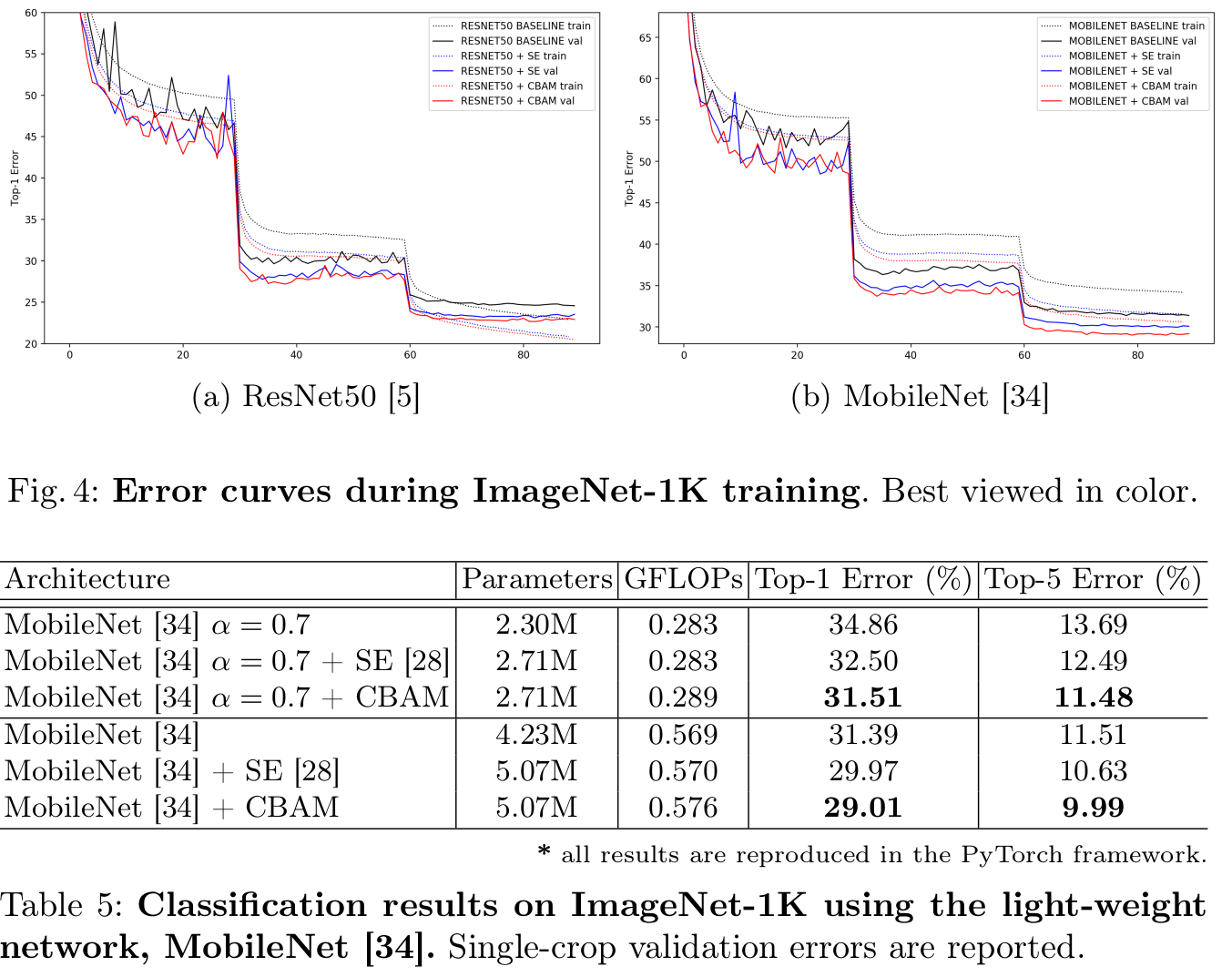
- MobiileNet에도 성능이 향상됨 $\to$ edge device에도 적합함
-
Grad-CAM 분석
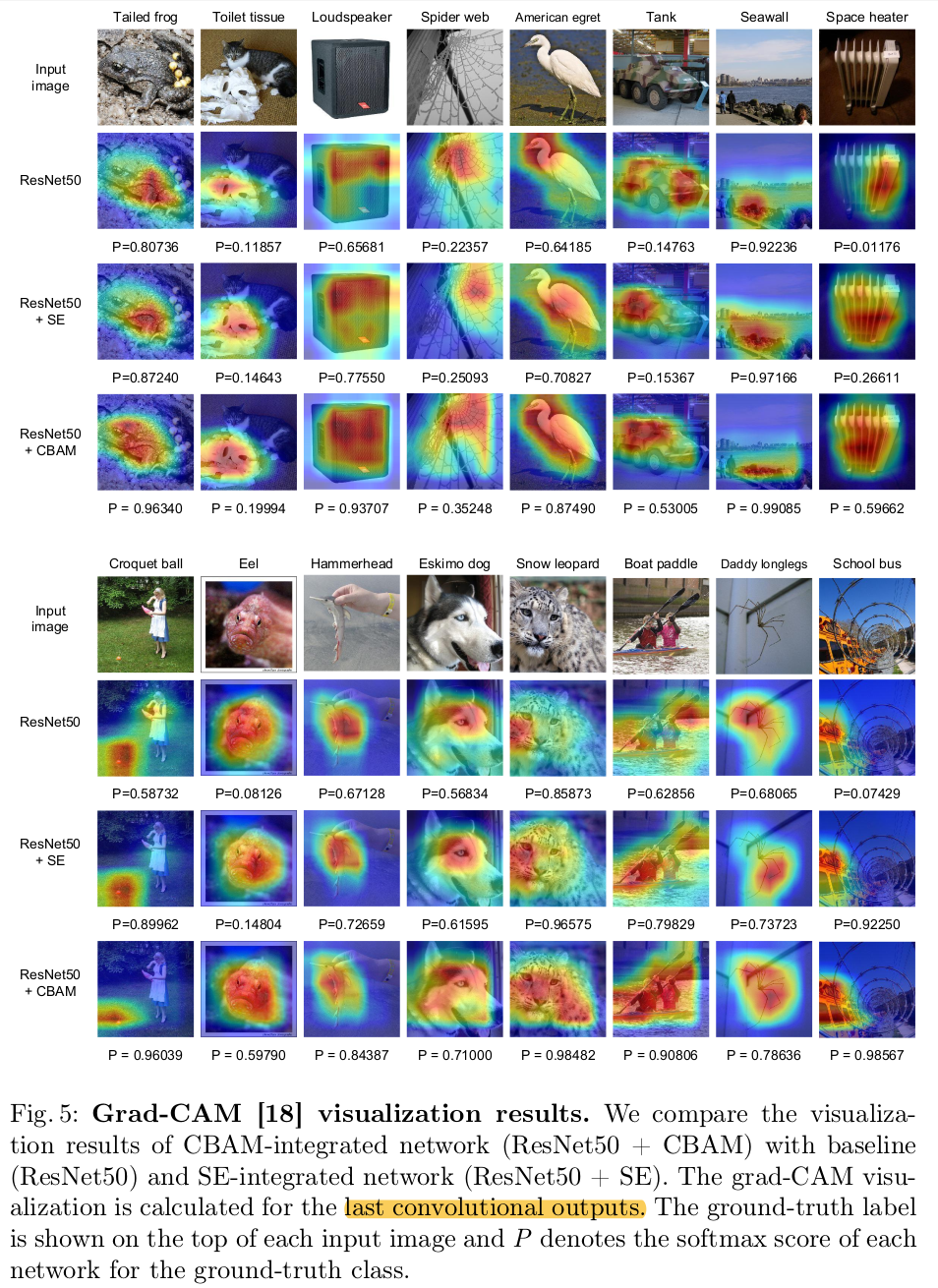
- Grad-CAM분석 결과, performance boost는 정확한 attention과 (그로 인한) noise reduction으로 해석됨
-
OD task 결과
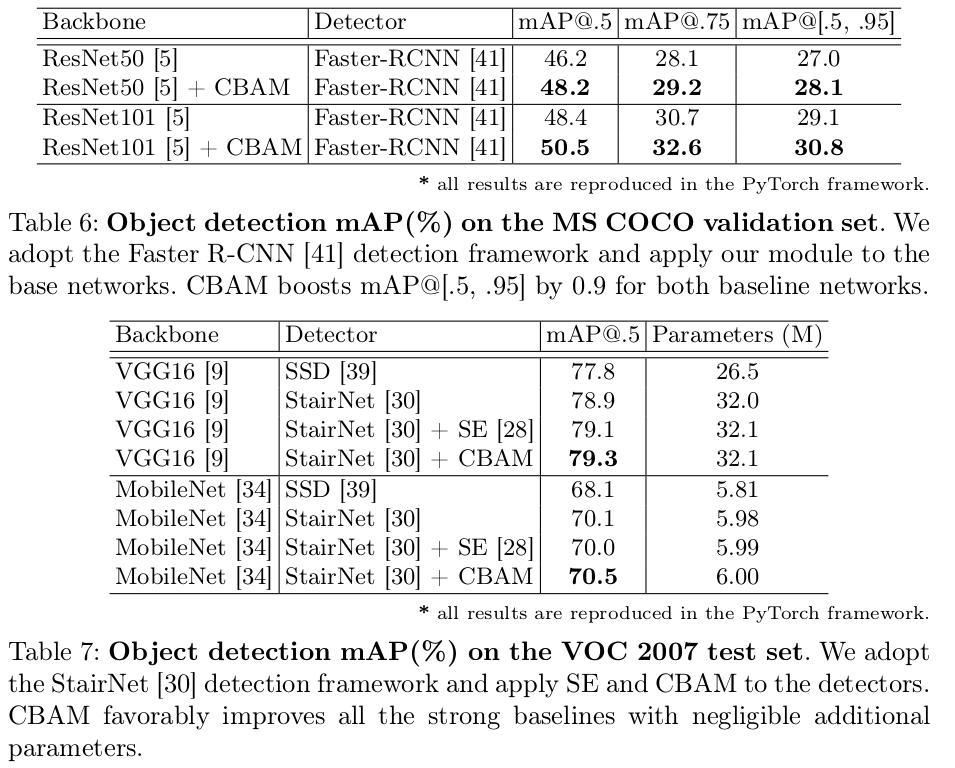
- one-stage, two-stage 모두 성능 향상을 보임