[WebAgent] The BrowserGym Ecosystem for Web Agent Research
[WebAgent] The BrowserGym Ecosystem for Web Agent Research
- paper: https://arxiv.org/pdf/2412.05467
- github: https://github.com/ServiceNow/BrowserGym
- ICLR 2025 accpeted (인용수: 7회, ‘25-06-09 기준)
- downstream task: WebAgent Benchmarks (WebArena, VisualWebArena, etc)
1. Motivation
-
LLM & VLM agent의 등장으로 다양한 Web Task benchmark가 등장했으나, 중구난방으로 code가 개발되어, 공평한 agent의 성능평가가 힘듦 (research silos)
-
이는 곧 다양한 환경 셋업과 데이터 포맷 변환, 그리고 수동으로 agent를 각각의 benchmark에 맞추는 귀찮은 과정을 수반함
$\to$ agent benchmark를 집약한 framework를 제안해보자!
2. Contribution
-
공개된, 쉽게 사용 가능한, 확장성이 있는 framework인 BrowserGym ecosystem을 제안함
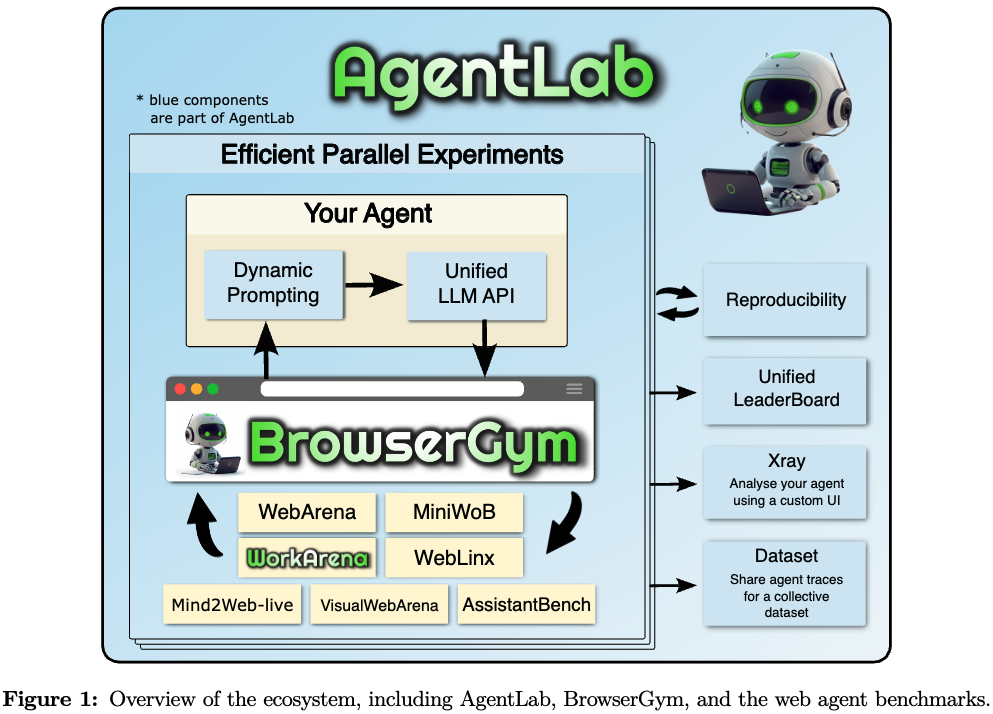
- AgentLab 기반: web agent를 만들기 위한 tool을 제공하며, large-scale 실험에 특화됨
- BrowserGym 기반: web task의 표준 interface를 제공함
- MiniWoB(++) 에서 최신 AssitantBench, VisualWebArena benchmark까지 제공함
-
large-scale 실험을 병렬로 쉽게 tool의 집합을 제공하는 AgentLab + BrowserGym 기반임
- 추가로 AgentXRay를 통해 개별 task에 대한 agent의 행동을 관찰가능함
- reusable building block 기능도 추가함
-
다양한 web agent experiment를 통해 최신 6개의 LLMs/VLMs (GPT-4, Claud 3.5, Llama 3.1, etc)의 결과를 report함
- 해당 결과는 BorwserGym leaderboard를 통해 공개함
3. BrowserGym
-
BrowserGym은 web agent를 위한 통합된 interface를 제공함
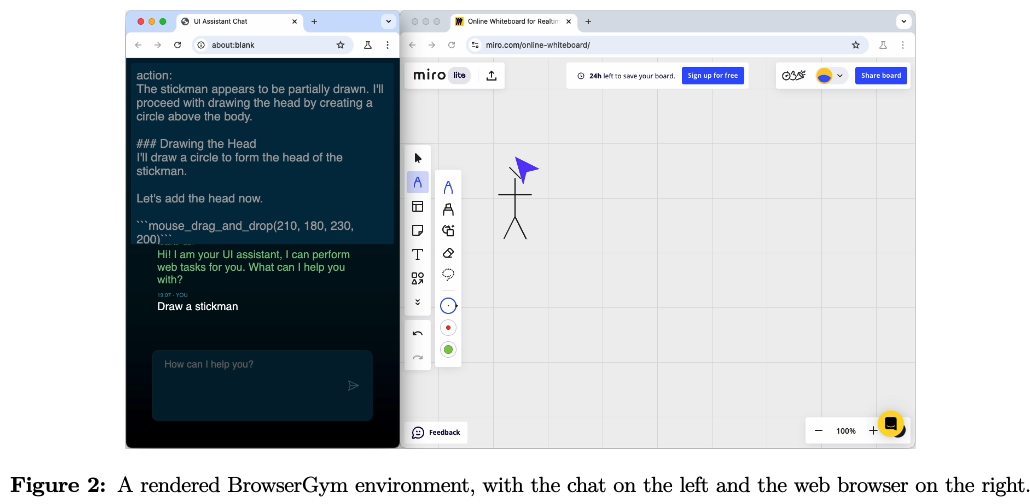
- 좌측: chatting 창 / 우측: web browser
- chatting: user / agent는 chatting창을 통해 상호작용함
- web browser: user / agent모두 action (ex. click, type, tab열기 등)을 수행 가능함
- 좌측: chatting 창 / 우측: web browser
-
Implementation
-
Agent 입장에서는 해당 interaction loop는 Partially Observable Markov Decision Process (POMDP)로 개념화될 수 있음
- environment는 현재 관측값 & reward를 제공함
- agent는 next action을 예측함
-
BrowserGym
-
표준 OpenAI Gym API를 따름
-
gymnasium interface를 통해 python으로 구현 가능함

-
Chromium browser를 통해 구현됨
-
Playwright library를 통해 browser와 소통함
-
-
3.1 Extensive Observation Space
- Main components: chat history, open tabs의 list, 현재 페이지의 content 정보 등

Structured page description
- 현재 페이지의 2가지 structured representations을 Chrome Developer Protocol을 사용해 추출
- raw DOM (Document Object Model)
- AXTree (Acessibility tree)
- + bid (unique id)를 element마다 부여함
Extra element properties
- BrowserGym ID (bid): html 내 개별 요소별로 unqiue id를 부여해 애매모호한 interaction을 방지함
- bbox (
left, top, width, height): 4-tuple - visibility ratio (
visibility): 0~1 값 사이. Set-of-Marks prompting에 사용 가능한지 여부 체크용.
Screenshot
- raw RGB 형태로 제공
Open tabs
- active page뿐만 아니라, 열린 page에 대해서도 agent는 접근 가능
active_page_idx, open_pages_urls, open_pages_titles
Goal and chat messages
- user instruction을 추출하는 두 가지 방법
- 명시적인 task goal (
goal_object) - Chat history를 통한 방법 (
chat_messages)
- 명시적인 task goal (
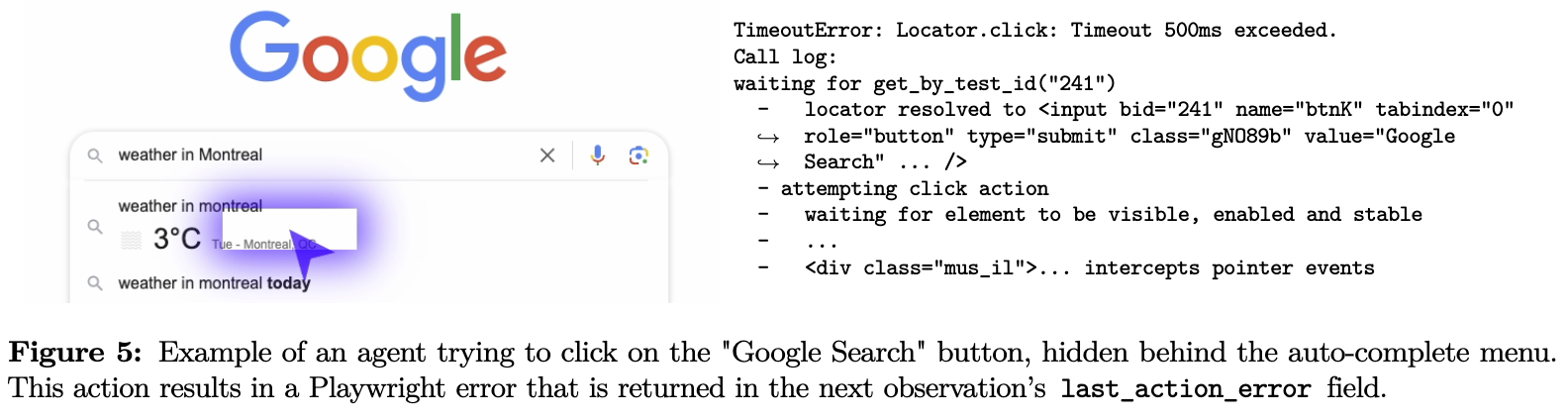
Error feedback
-
최종 수행된 action에 대한 error (
last_action_error)만 제공함 -
loop가 종료되지 않고, 해당 내용을 feedback함으로써, agent로 하여금 self-correction을 next step에서 수행하도록 유도함
3.2 Expandable Action Space
-
BrowserGym의 action space 근간은 executable python code이다.

-
Agent는 Playwright page object에 접근할 수 있고,
send_message_to_user(text)와report_infeasible(reason)으로 chatting창과 상호작용 & task 종결을 할 수 있다. -
action_mapping_function을 통해 제한된 action에 대해서만 수행가능하다.
Action mapping
action_mapping- environment의 input action을 executable python code로 변환해주는 기능
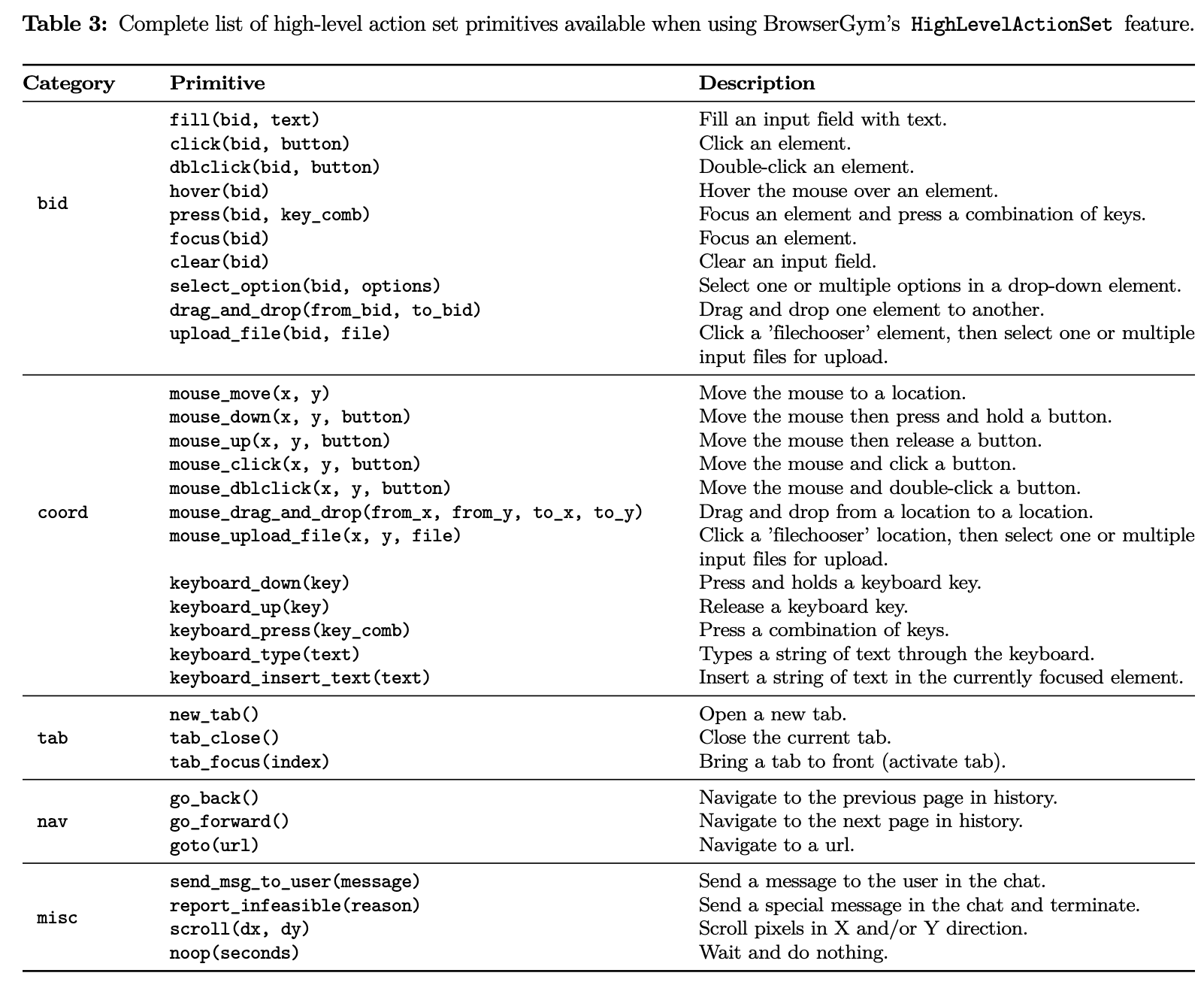
High-level action set
-
predefined actions

3.3 Extensibility: create your own task
-
새로운 task를 처음 접해보는 사람이 수행할때 두 가지만 정의해주면 된다.
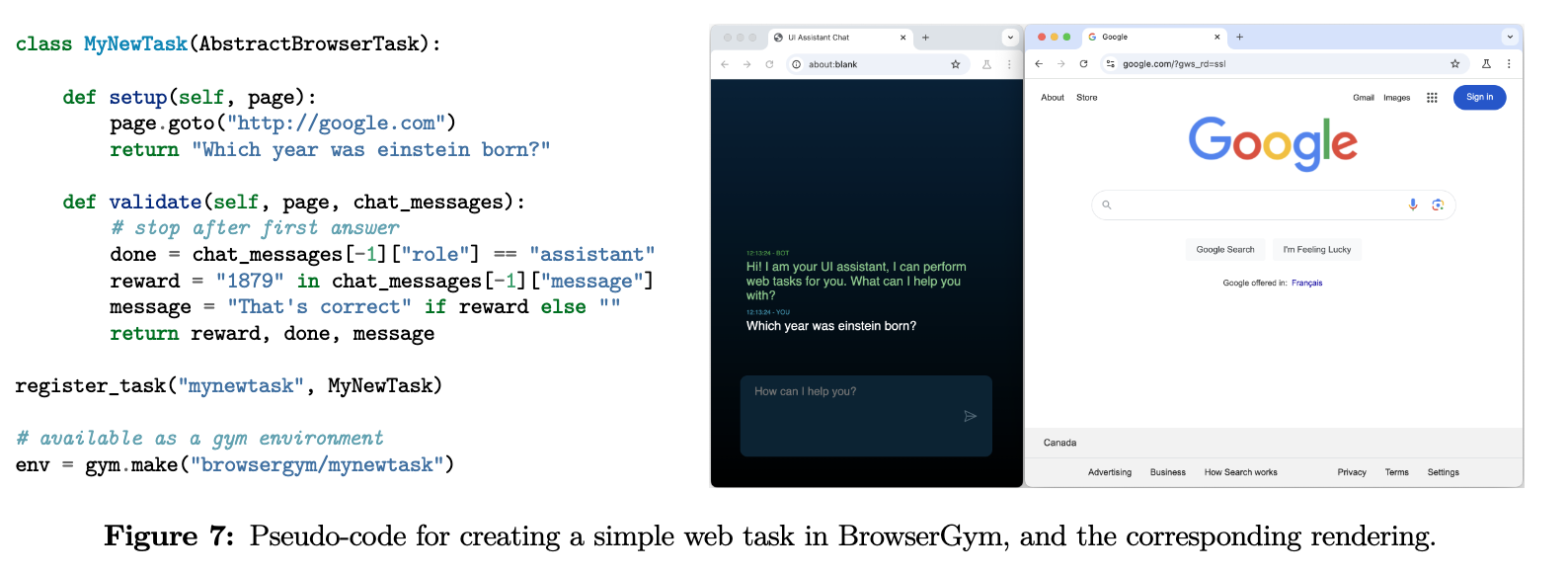
Setup: 빈pageobject로부터 시작해서, task의 시작점을 호출하고, task에 대한 설명을 raw string 혹은 openai-style message 형태 (multi-modal)로 목표를 제공한다.Validate: agent action이 수행된 후에 호출되며, task의 완료 여부를 체크한다. 마지막에는 agent에 scalar reward + done flag를 제공한다.
4. Unification of Web Agent Benchmarks
-
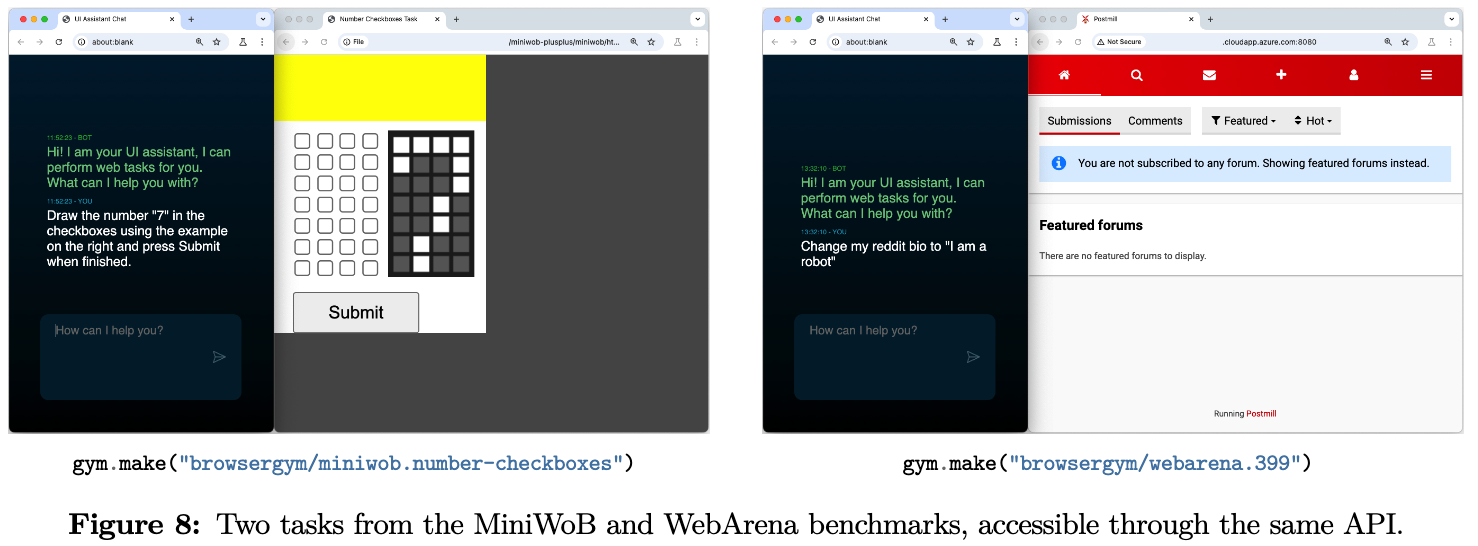
기존의 web benchmark (6개) + WebLINX, VisualWebArena, AssistantBench를 제공함
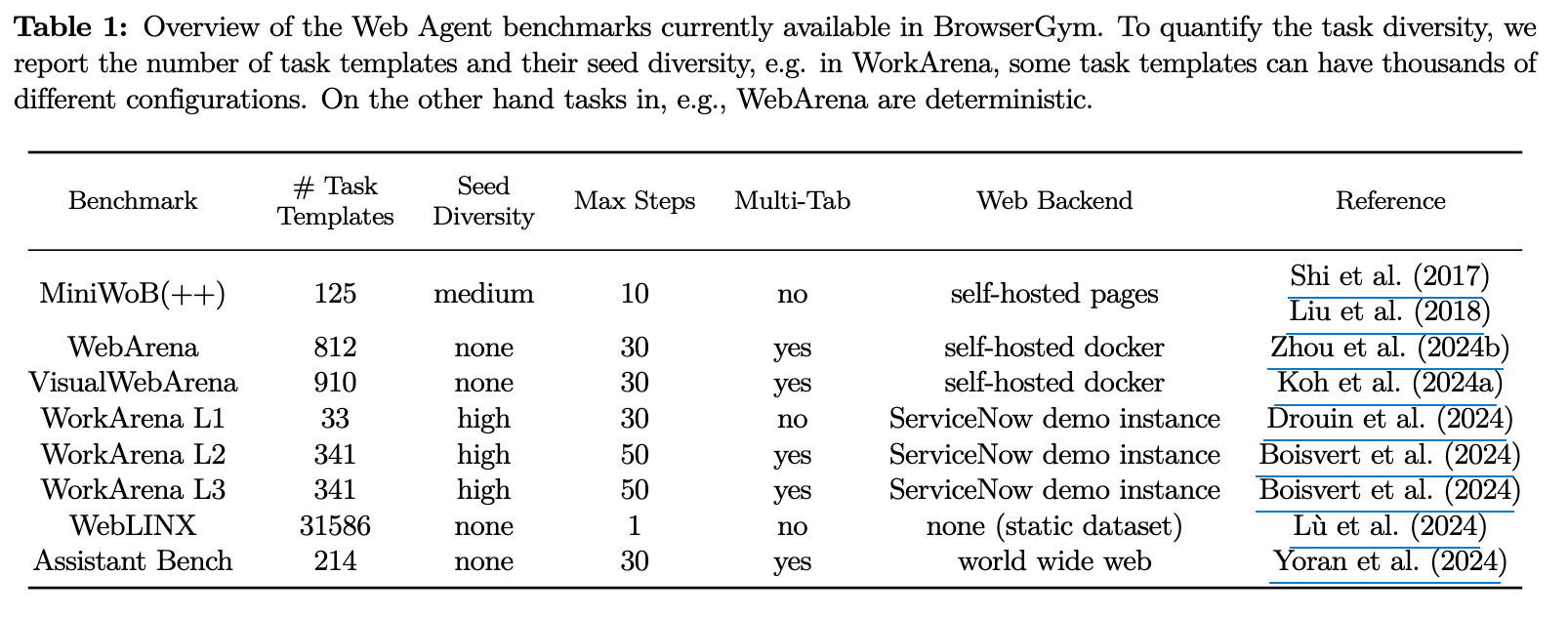
-
Gymnasium interface 기반 구현됨
-
장점
- silos를 깨부심: 통합된 benchmark는 general-purpose web agent 구축에 기여함
- 연구를 촉진함: 상호 비교의 시간 & 노력을 절감함
- noise를 제거함: 다양한 ablation 실험을 평가함
Task coverage
- MiniWoB
- 단일 HTML page 접근만 가능
- JavaScript로 평가
- 병렬 처리 지원
- WebArena
- 6 domain의 real-world websites를 모방하기 위해 docker container 기반 self-hosting함
- 새로운 agent evaluation전에 초기화 진행해야 함
- 평가방식은 logic rules (URL match, message content, HTML content) 혹은 LLM-as-a-judge활용한 Semantic Match
- VisualWebArena
- 기존 WebArena에서 2개 + 새로운 1개를 추가함
- vision-based tasks에 특화된 benchmark임 (“Find a pair of shoes that looks like this image”)
- open-source VLM (
blip2-flan-t5-xl)의 visual matching에 영향을 받음
- WorkArena
- 백앤드 플랫폼 (self-hosted server)은 주문형으로 사용가능한 무료 ServiceNow 사용자 계정으로 Personal Developer Instance (PDI)가 필요함
- 대규모 병렬처리 가능
- AssistantBench
- 214개의 realistic & time-consuming open-domain tasks로 구성됨
- 525 web page를 browsing하고, 258개의 서로 다른 website를 정확히 답변하는 task임 (Information Retrieval tasks)
- general assistant task / domain-specific task로 구성됨
- WebLINK
- static & supervised benchmark임
Metadata
- domain-specific attributes (ex. task 난이도, task 카테고리)
- default train/val split
- task 순서
5. AgentLab
- Agent experiment를 BrowserGym에서 쉽게 연동할수 있게해주는 tool이다.
Studyobject를 정의하여 다양한 benchmark evaluation의 실험들을 병렬로 organize할 수 있다.- 완료된 study는 AgentXRay를 통해 조회할 수 있다.
- Agent 특성상 동적 환경 변화로 모니터링이 어렵기 때문에, reproductibility를 보조하는 기능이 있다.
- 새로운 agent를 생성할 builing block도 제공한다.
5.1 Launching experiments
- agent evaluation 구현
study = make_study(
benchmark="miniwob", # or "webarena", "workarena_l1" ...
agent_args=[AGENT_4o_MINI],
)
study.run(n_jobs=5)
- 수동 agent 구현 및 오류 task만 추출
study = Study.load("/path/to/your/study/dir")
study.find_incomplete(include_errors=True)
study.run()
5.2 Parallel experiments
-
1개의 study를 처리하는데 수천개의 episode로 실험해야함 $\to$ 병렬처리가 필수임
-
backend로
ray혹은joblib을 사용하여 해결 -
대부분의 compute requirements가 outsourced (LLM API, TGI server, web server) 되어있으므로, 실제 job의 compute requirement는 작음
$\to$ labtop기준 20 tasks / server machine 기준 50-100 tasks 병렬 처리 가능
$\to$ 대부분의 bottleneck이 LLM API 호출하는 부분임
$\to$ (Visual)WebArena의 경우, 2~4 tasks만 병렬처리 가능
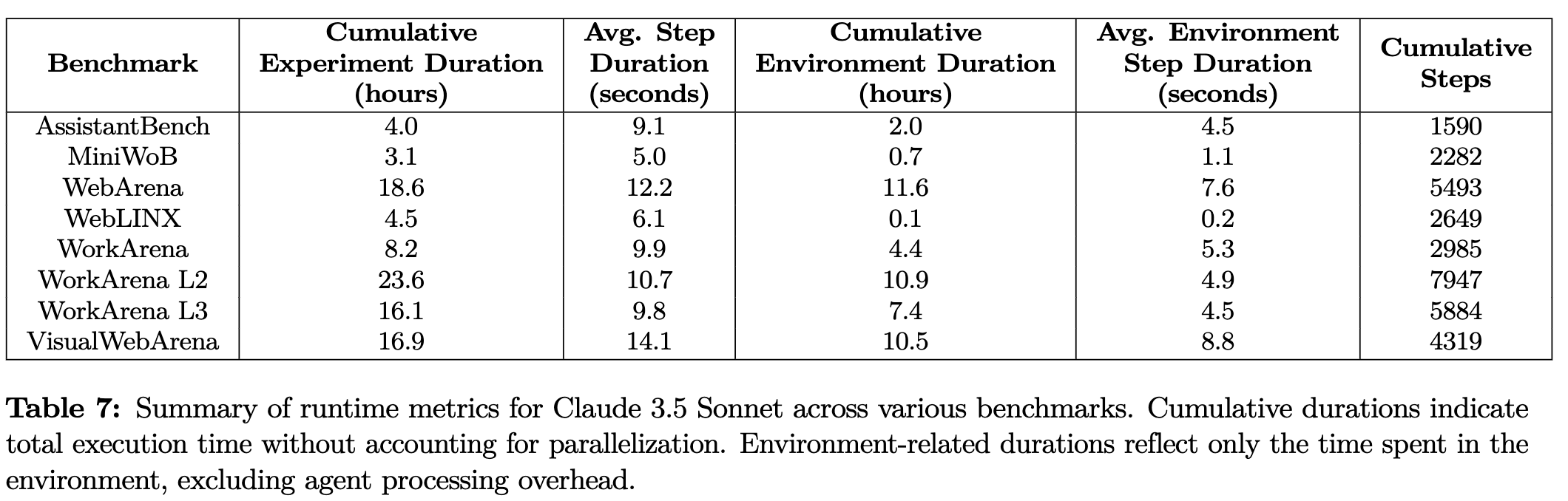
- 병렬처리 안한 상태
5.3 AgentXRay
-
Gradio-based interface
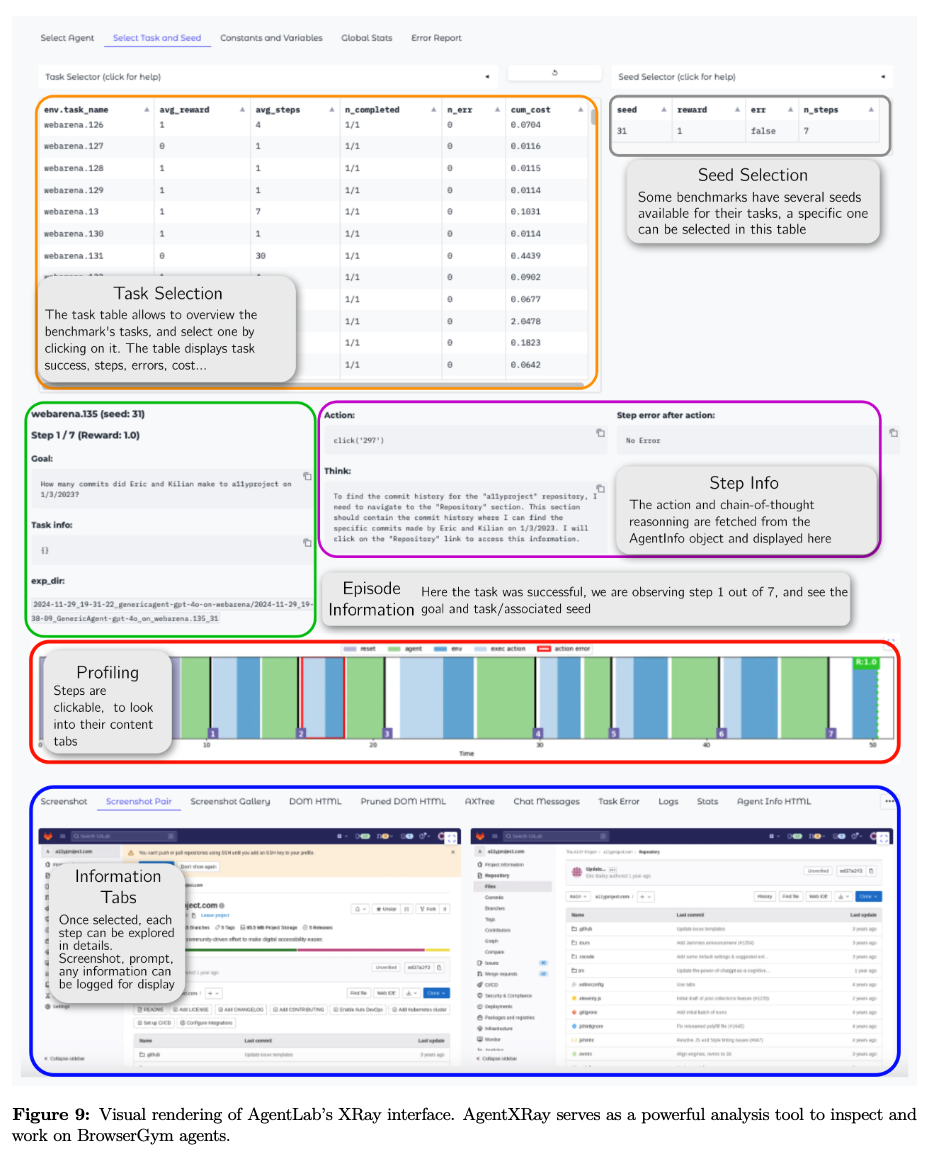
5.4 Reproducibility
- 여러 요인으로 인해 webagent 결과를 reproducibility를 하기 힘들다. BrowserGym은 이를 해결하는 방안을 제시한다.
5.4.1 Factors affecting reproducibility
- Software version: Playwright 등 software stack의 version에 따라 agent의 행동이 달라질 수 있음 $\to$ package version fixing이 필요함
- API-based LLMs silently changing: commercial LLM은 fixed version이라 하더라도 미세하게 변경되고 있음. (최신 web knowledge 추가)
- Live websites: website design의 변화, content의 availibility 여부, language setting 등 notice 없이 변경됨.
- Stochatic Agents: non-deterministic한 LLM의 특성으로 temperature를 0으로 해결책임
- Non-deterministic tasks: task 자체에 어느정도 stochastiscity가 있음. seed 고정으로 해결함.
5.4.2 Reproducibility Features
- Standard observation & action space
- Package versions
- Reproducability journal:
study.append_to_journal()- agent name, BrowserGym version, AgentLab version, benchmark name, metadata, experiment performances, etc
- Reproduced result in the leaderboard
- community에 동기부여
- ReproducibilityAgent
GenericAgent의 실험 결과를 재현하기 위해ReproducibilityAgent를 선언함
5.5 Extensibility: create your own agent
-
Agent class를 상속받아, 최소한의 구현만 하면 됨

get_action: agent의 action logic을 설계하는 핵심 부분- action을 string 형태로 출력
agent_info: agent의 다양한 정보를 포함 (재현, 등 목적)
-
AgentArgs-
make_agentmethod를 통해 agent를 pickle화하여 다른 process에 전달이 용이하도록 함
- MyAgentArgs는
PYTHONPATH경로에서 조회되어야 함
- MyAgentArgs는
-
-
Dynamic Prompting
-
HTML DOM 문서는 max token이 벗어나는 경우가 빈번하므로, input token 갯수를 자동으로 조절하는 기능 (by
fit_token)
-
5.6 Extensibility: Plug your own LLM / VLM
- 기본 LLM class를 제공하므로, 쉽게 custom LLM 구현 가능
BaseModelArgsAbstractChatModel
- cost & token tracking 기능도 기본적으로 탑재됨
6. Experiments
6.1 Setup
-
Models

-
Datasets
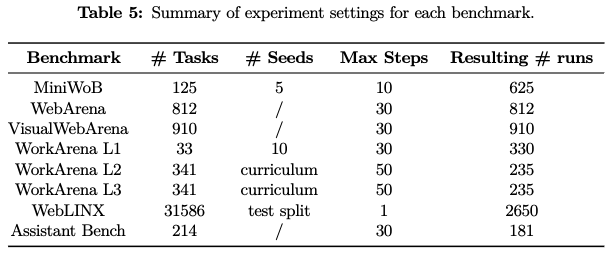
6.2 Results
-
정량적 결과
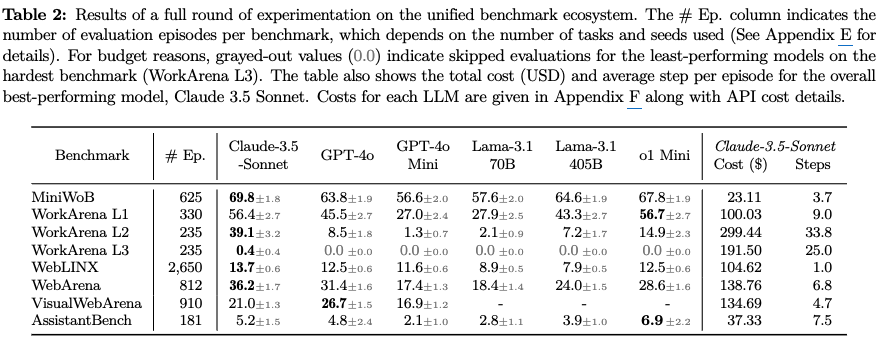
-
Tool Use를 학습한 Claude-3.5-Sonnet이 성능이 제일 좋음
-
Total tokens & $/M tokens & API Cost
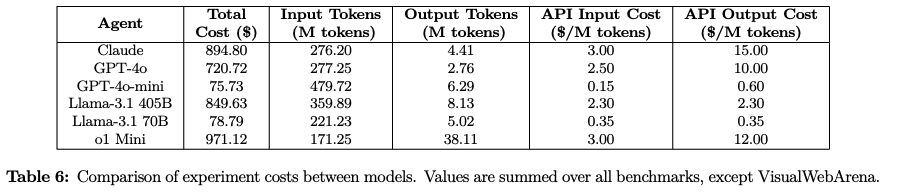
-
7. Related Works
7.1 Web Agent Benchmarks
- MiniWoB/MiniWoB++: web based task의 근간이 되는 evaluation metric을 기본적인 web interactions (form filling, button clicking)에서 제안함
- WebShop: 비교적 복잡한 e-commerce 시나리오를 대상으로 agent로 하여금 user의 관심도 & 제약에 따른 제품의 catalogs를 navigate 수행함
- Mind2Web: 더 나아가 multi-step interaction을 2,000 human tracesfmf cnlgkqgkdu 137 real-world website를 기반으로 하는 benchmark
- WebVoyager: live, online benchmark로, 15 유명한 websites를 근간으로 하는 real-world tasks로 구성됨
- WebCanvas: Mind2Web의 static environment를 개선하여 ㅐnline benchmark화한 Mind2Web-Live를 제안함
- WebArena/VisualWebArena/VideoWebArena: agent를 live website와 상화작용하는 혁신을 가져온 benchmark. Agent의 real-world variability in website를 평가하며, content의 동적인 특성을 반영함.
- VisualWebArena는 최신 web interface를 시각적으로 이해하는지를 평가함 (e-commerce에서 visual search, product image comparison, spatial reasoning about interace layouts 등)
- WebLINX: agent의 instruction-following 능력에 집중하며 100K human interactions (155 real-world websites)로 구성됨
- AssisantBench: 214 realistic task로 구성되며, agent가 여러 website간의 navigate하면서 synthesize 정보를 gather하는 능력을 평가
- MMInA: 여기서 더 나아가, 1,050 multimodal task로 구성되어 multiple websites간에 navigate를 하며 visual & textual 정보를 naturally compositional task를 수행하며 평가함
- GAIA: QA benchmark로, agent가 다양한 web source로부터 항해하면서 취득한 정보 기반 정답을 예측하는 능력을 평가.
- 그외에 AgentBench, AndroidBench, OSWorld, Widnows Agent Arena는 부분적으로 web task를 수행함
- ST-WebAgentBench: 최초로 회사의 정책과 safety 요구사항을 반영하는지를 중점적으로 하여 만든 benchmark
7.2 Web Agent Implementations
- HTML element와 직접적으로 상호작용하는 기법
- VLM을 활용하여
- web element를 screenshot을 이용해 grounding하는 기법
- pixel-level로 element와 상호작용하는 기법
- Agent의 reasoning 능력 향상을 위해 prompting / tuning하는 다양한 연구 진행함
- prompting & planning & search에 대한 연구들
- chain-of-thought
- tree-of-thought
- ReAct
- RCI
- training 기법들
- prompting & planning & search에 대한 연구들
- Web agent 개발을 위한 framework를 제안하는 연구들도 많음