[Agent] BannerAgency: Advertising Banner Design with Multimodal LLM Agents
[Agent] BannerAgency: Advertising Banner Design with Multimodal LLM Agents
- paper: https://arxiv.org/pdf/2503.11060
- github: X
- archived (인용수: 0회, 25-08-02 기준)
- downstream task: Banner 자동 디자인
1. Motivation
-
Banner 광고 제작은 유저의 주의를 끌어들임과 동시에 전달하고자 하는 메세지를 분명히 전달해야 하므로, search space가 광범위해 제작 과정이 어렵다.
- 다양한 템플릿 크기 지원
- 다양한 디자인 요소 사용 (brand logos, product images, click-to-action(CTA) buttons, backdrops(배경), decorative elements, typography, etc)
- 다양한 sector의 청취자
-
디자인 보조하는 agent에 대한 연구는 제약이 있었다.
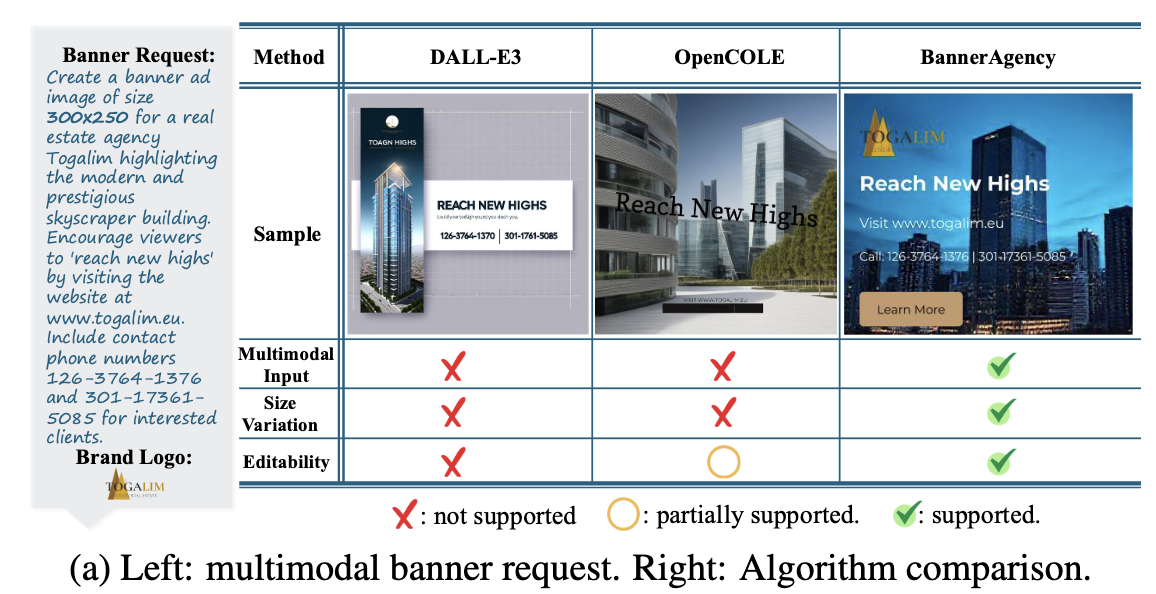
- 창의적인 design process만 다룬다. (OpenCOLE)
- Pixel기반의 이미지로 처리해서, editibility가 떨어진다. (DALL-E3, scene-text rendering models)
$\to$ ediltable하고, fully automated banner ad design하는 system을 제안해보자!
2. Contributions
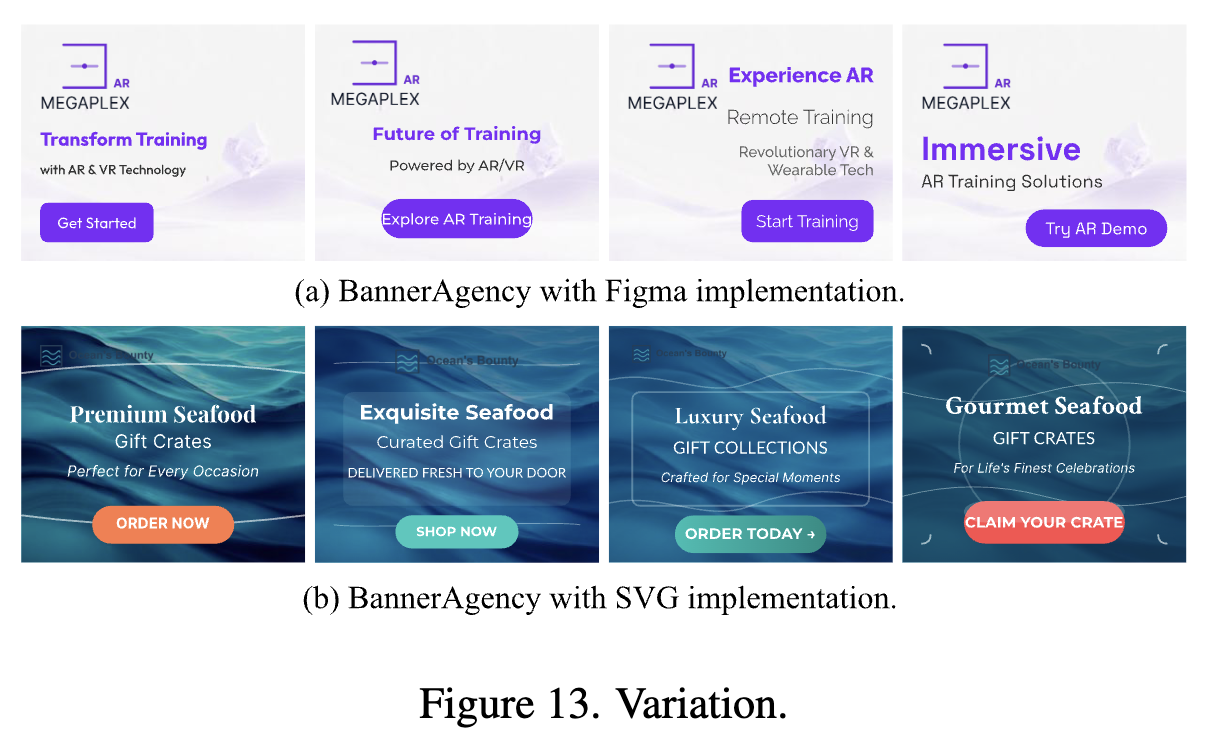
- Figma / SVG format으로 편집 가능한 Banner를 전략 기획부터 기술적 구현까지 professional design workflow를 시뮬레이션하는 BaneerAgency를 제안함
- input: branch logo 이미지, 광고주의 요구사항
- output: 모든 요건을 만족하는 배너 디자인 (SVG format / Figma format)
- BannerRequest400 benchmark를 제공함 (100개의 uniquely created logo & 400개의 다양한 target audience & 주요 목표의 banner 디자인 요구사항)
- BannerAgency의 고품질 & 다재다능한 editable banner 능력을 보임
3. BannerAgency
-
overall diagram
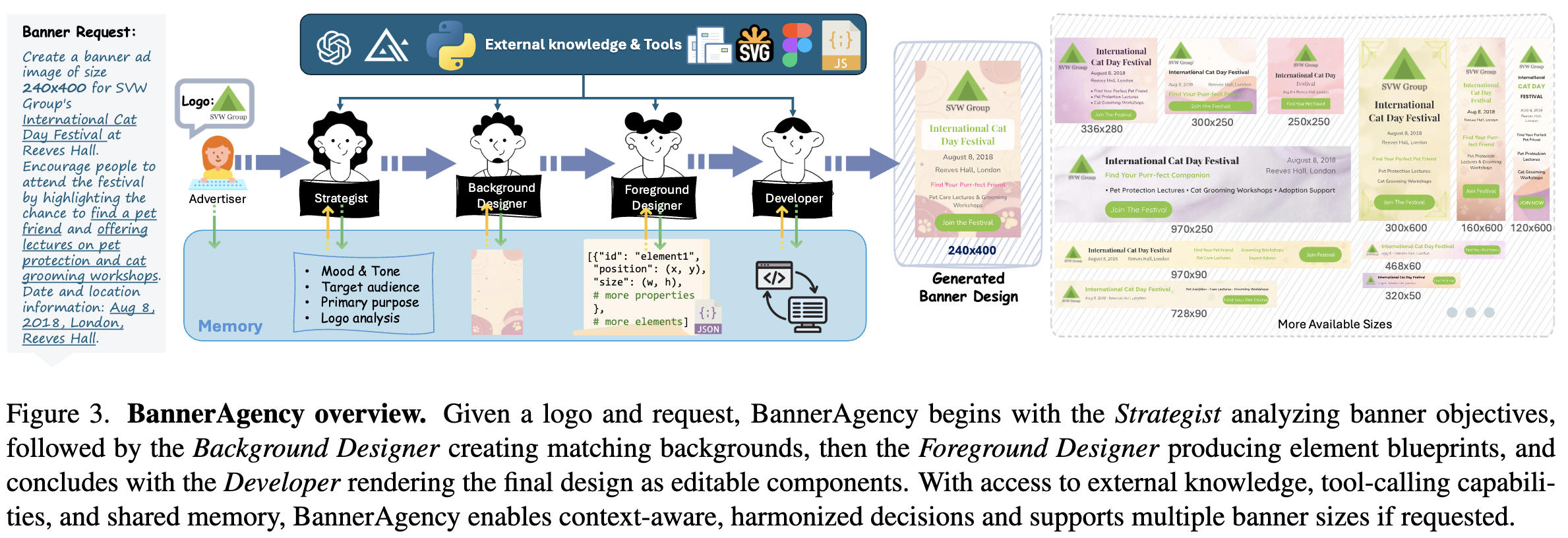
- MLLM: 4개의 agent (Strategist, Background Designer, Foreground Designer, Developer)를 구현
- external tool calls 가능
- Memory
- MLLM: 4개의 agent (Strategist, Background Designer, Foreground Designer, Developer)를 구현
3.1 BannerAgency
-
Strategiest
- input
- text: 광고주가 제공한 brand guidelines, specifications (logo, desired dimensions) 등의 요청사항 (ground requirements)
- image: brand logos
- output
- key banner objectives (mood, tone, target audience, primary purpose)
- logo를 padding을 하여 가다듬음
- input
-
Background Designer
-
input: Strategist가 제공한 key objectives
-
output: 광고주의 요청사항 + 로고의 특성 + campaign의 목적에 맞는 T2I 모델에 들어갈 prompt를 생성
-
ReAct agent기반으로 구현되며, Tool 3가지를 사용함
-
FindImagePath: 광고주가 제공한 background image가 있는지 판단하는 tool -
TextChecker: 생성된 이미지에 text 존재여부를 체크하는 tool. image내 text가 있으면, forground agent를 혼동시킬 수 있으므로 self-refining-loop를 통해 해당 text를 제거하는 새로운 prompt를 생성

- T2I 모델이 생성한 이미지중 aspect ratio를 만족하면서 가장 좋은 해상도를 갖는 이미지를 채택함 $\to$ banner size로 resize
-
-
-
-
Foreground Designer
-
BannerAgency의 핵심 창작 모듈. overlap & align을 잘되도록 하기 위해 reference properties 기반으로 relative position을 적용.
-
input
- background image
- logo image
-
output

- JSON-structured schema
- foreground element의 blueprint를 저장 (position, size, styling, call-to-action buttons, decorative elements, etc)
$\to$ pixel-level 출력이 아닌, json 형식으로 design decision을 결정함으로써 visual coherence 만족함과 동시에 element-level editability 확보가 가능해짐
- JSON-structured schema
-
-
Memory-augmented iterative design refinement
-
프로페셔널 디자인 생태계에서는 외부로부터의 피드백을 바탕으로 반복적인 refinement는 필수임
-
AgentBanner에서는 external design reviewer를 두어, 이를 시뮬레이션함
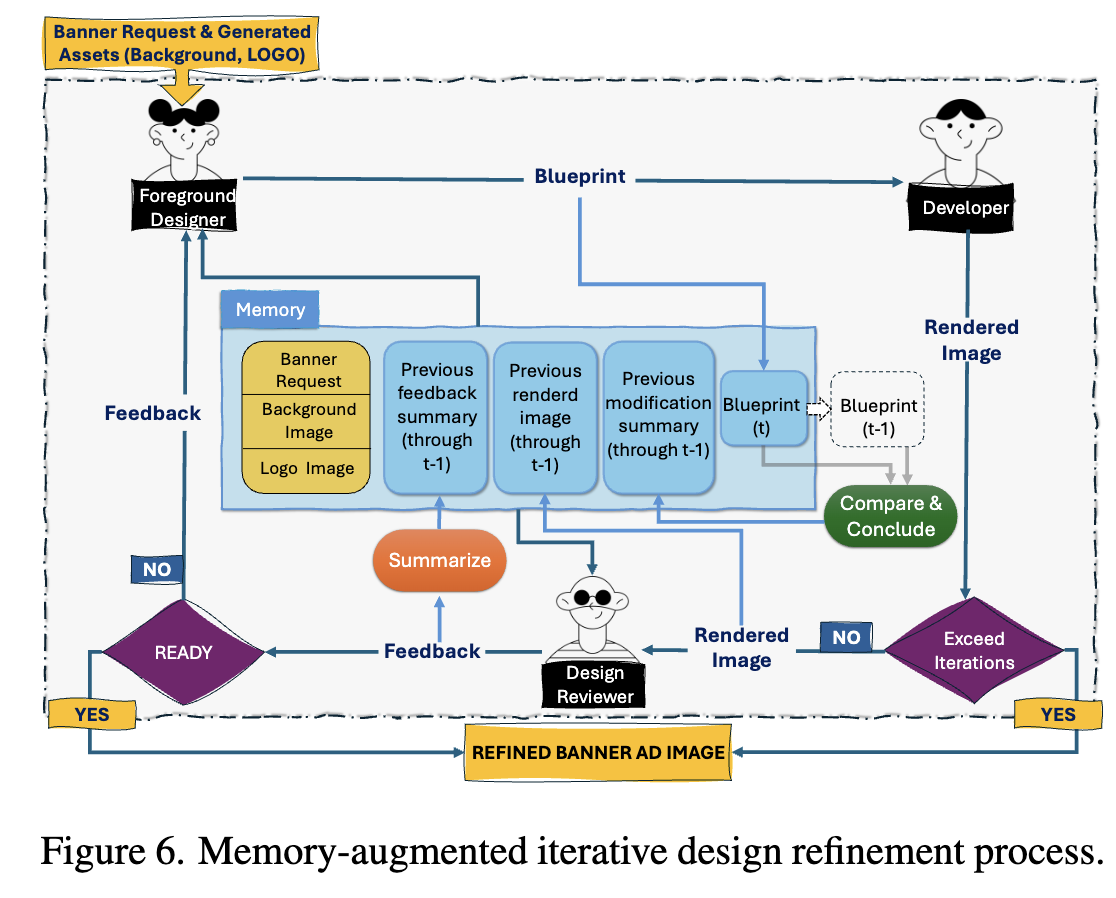
-
이전 step의 결과를 저장함으로써 출력 결과가 더욱 다양해짐
-
-
-
Developer
-
input
- blueprint created by Foreground agent
-
output
-
banner ad image (SVG code or Figma code)

- SVG code: XML기반으로 design element의 styling, position, dimensions 등을 표현
- Figma code: JavaScript기반으로 design element를 표현
-
-
3.2 BannerRequest400 Benchmark
-
현존하는 banner design benchmark의 한계
- DESIGNERINTENTION의 한계
- unimodality: text만 존재?
- designer의 request에 대한 구체적인 언급이 부족
- DESIGNERINTENTION의 한계
-
BannerRequest400 특징
-
Multi-modality
-
design logo와 광고주의 request를 pair로 가지고 있음
-
logo $\to$ DESIGNERINTENTION에서 가지고 design intention을 Claude3.5 Sonnet으로 생성 및 전문가의 review와 refinement를 거쳐 믿을만한 logo의 심미적 아름다움을 반영 $\to$ GPT-4o를 가지고 400개 request / 13개의 banner dimensions 총 5,200개의 multimodal banner benchmark를 생성

-
-
4. Experiments
-
Algorithms
-
Pixel-based
- DALL-E3
- FLUX.1-schnell
-
Graphic Design
- OpenCOLE
-
BannerAgency backbone
-
ChatGPT-4o
-
Claude-3.5 Sonnet
-
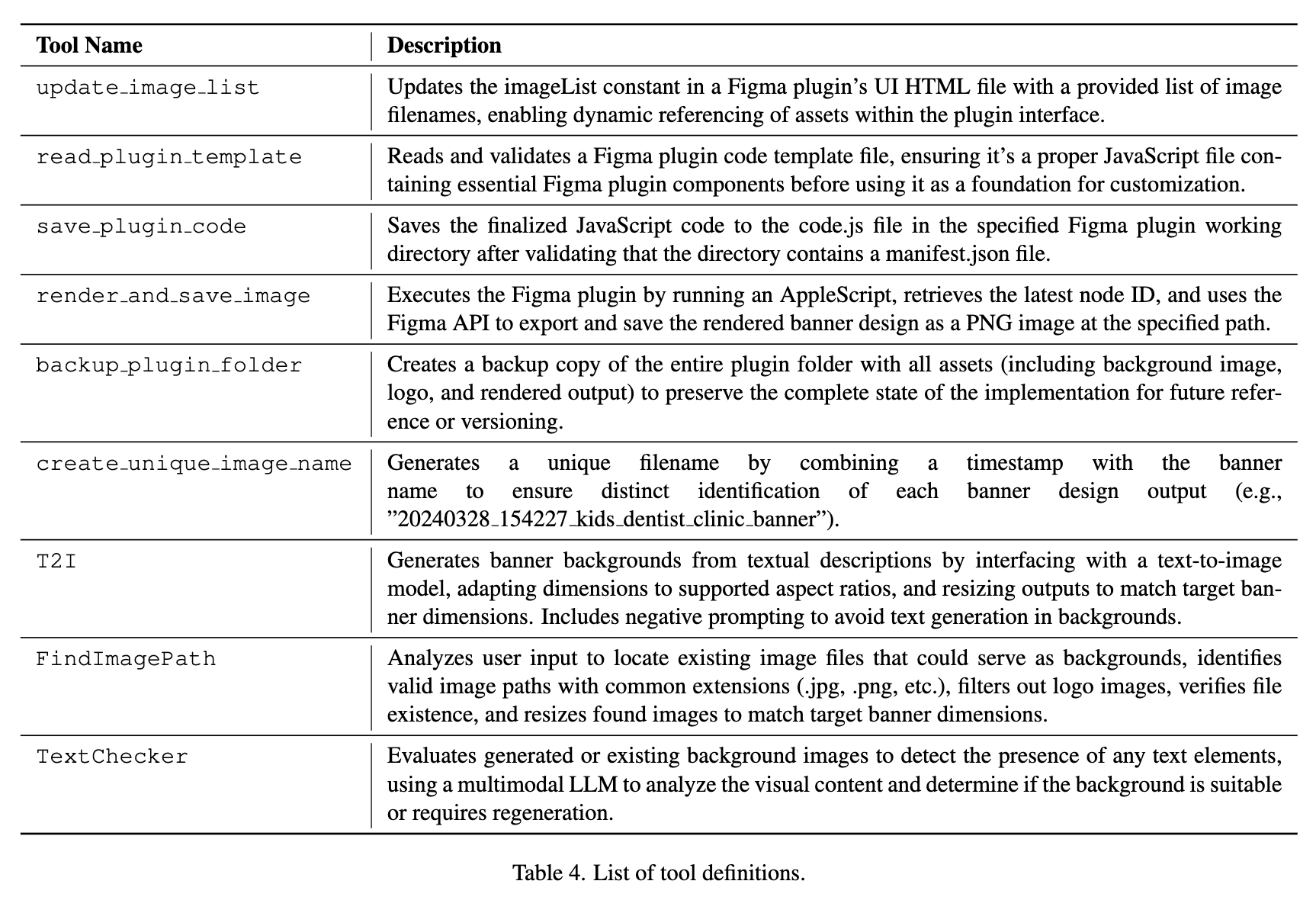
Tool Definitions
-
-
-
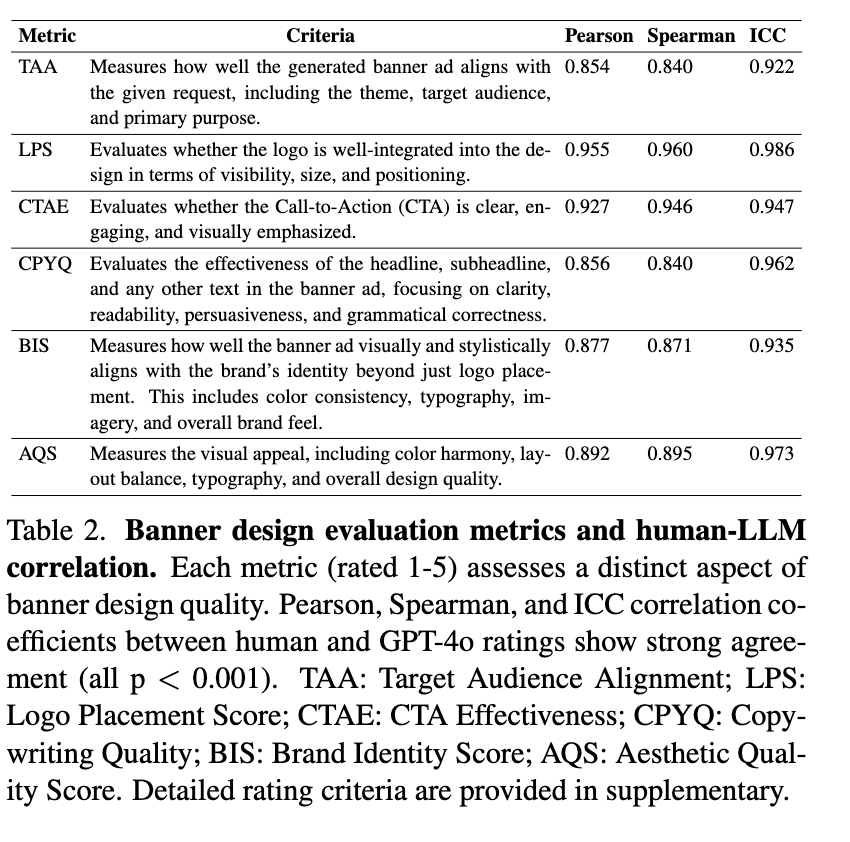
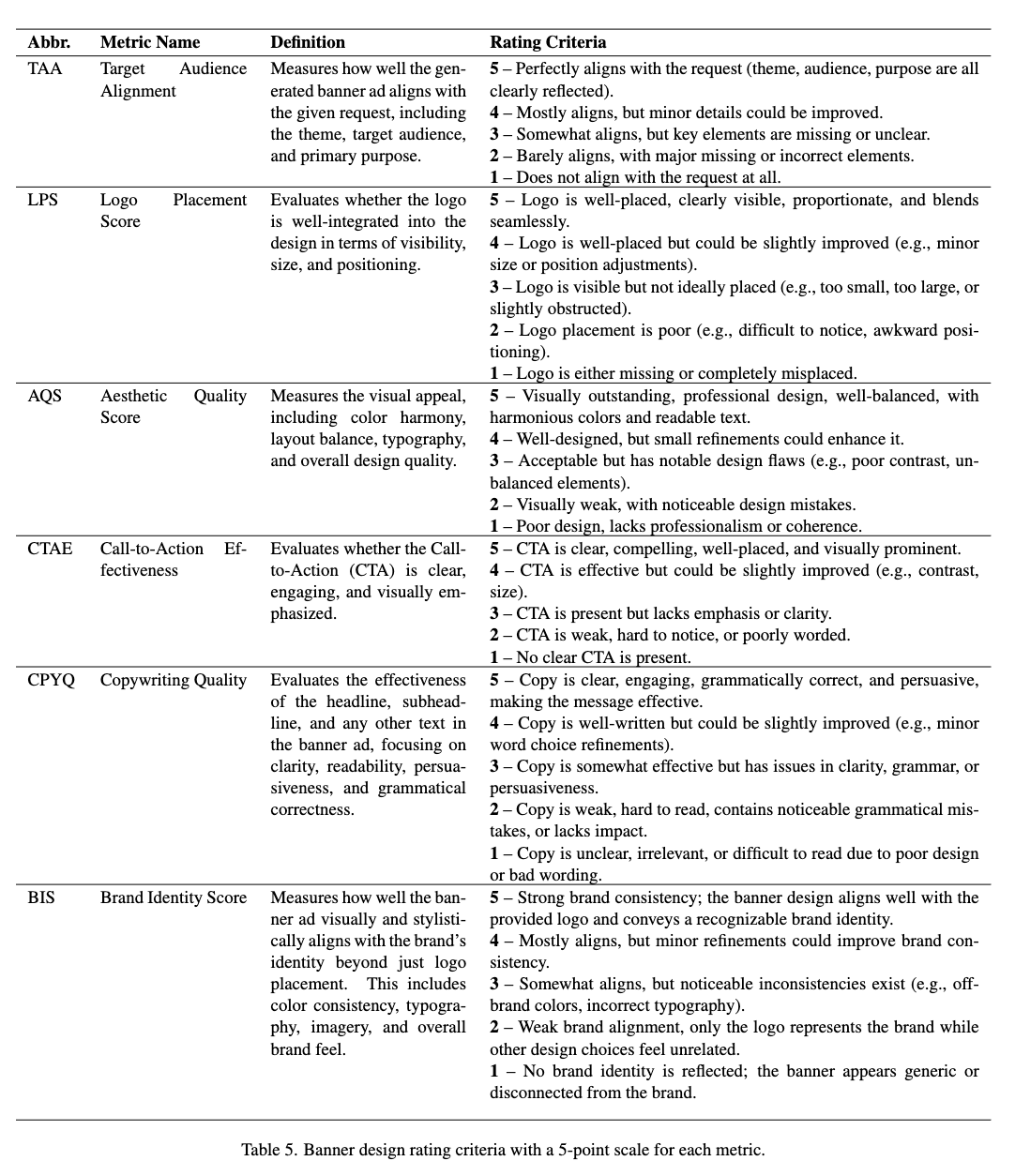
Metrics
-
-
Human Study
-
20명의 참석자 대상으로 20개의 random selected requests에 대해 5개의 variant를 두고 비교 실험함
-
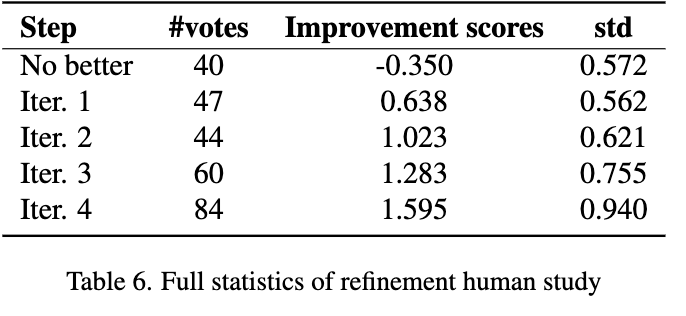
Refinement progress가 효과적인지 추가 입증을 위해 15명의 참석자를 대상으로 20개의 서로다른 banner design에 대해 4번 iteration을 돌며 design이 점차 나아지는지 실험함
-
GPT-4o의 scoring과 사람의 scoring간의 alignment를 실험함 $\to$ Table 2. 참고
-
17-19명의 participant가 25개 이미지를 대상으로 5개의 metric에 대해 점수를 부여함
-
-
-
정량적 결과
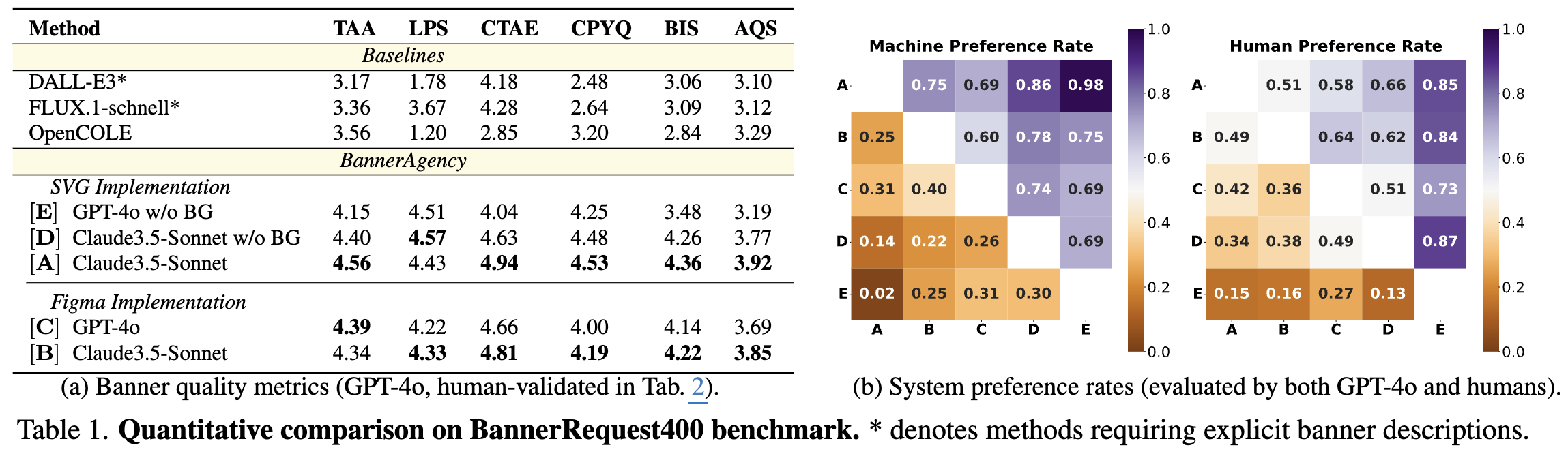
- Claude3.5-Sonnet > GPT-4o (A vs. D / B vs. C)
- Figma code == SVG code (human만 보면. human + GPT-judge를 보면 Figma > SVG)
- Background image 유무가 visual appearcne 성능에 매우 큰 영향을 줌 (A vs. E)
-
정량적 결과 2
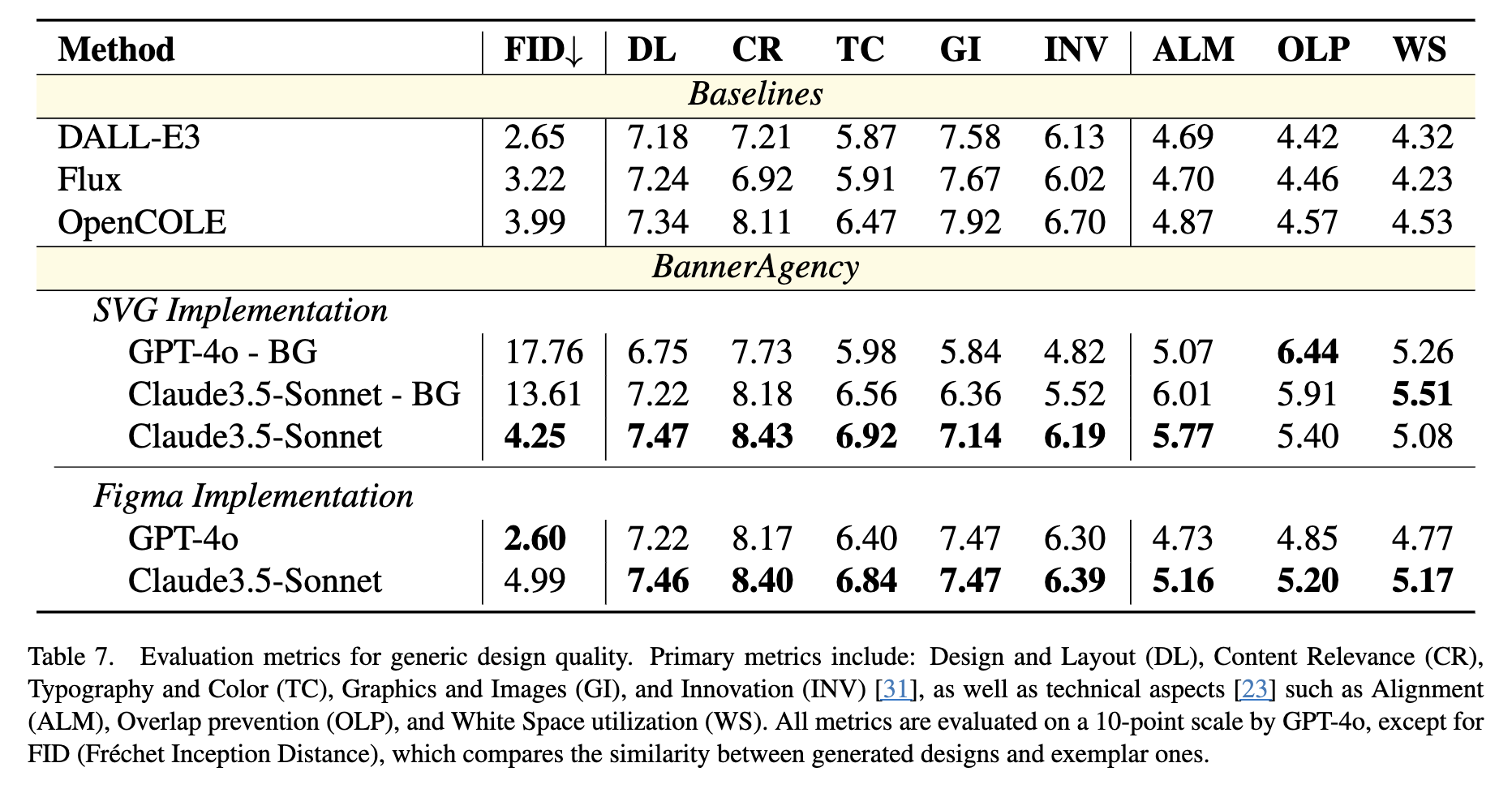
-
정성적 결과
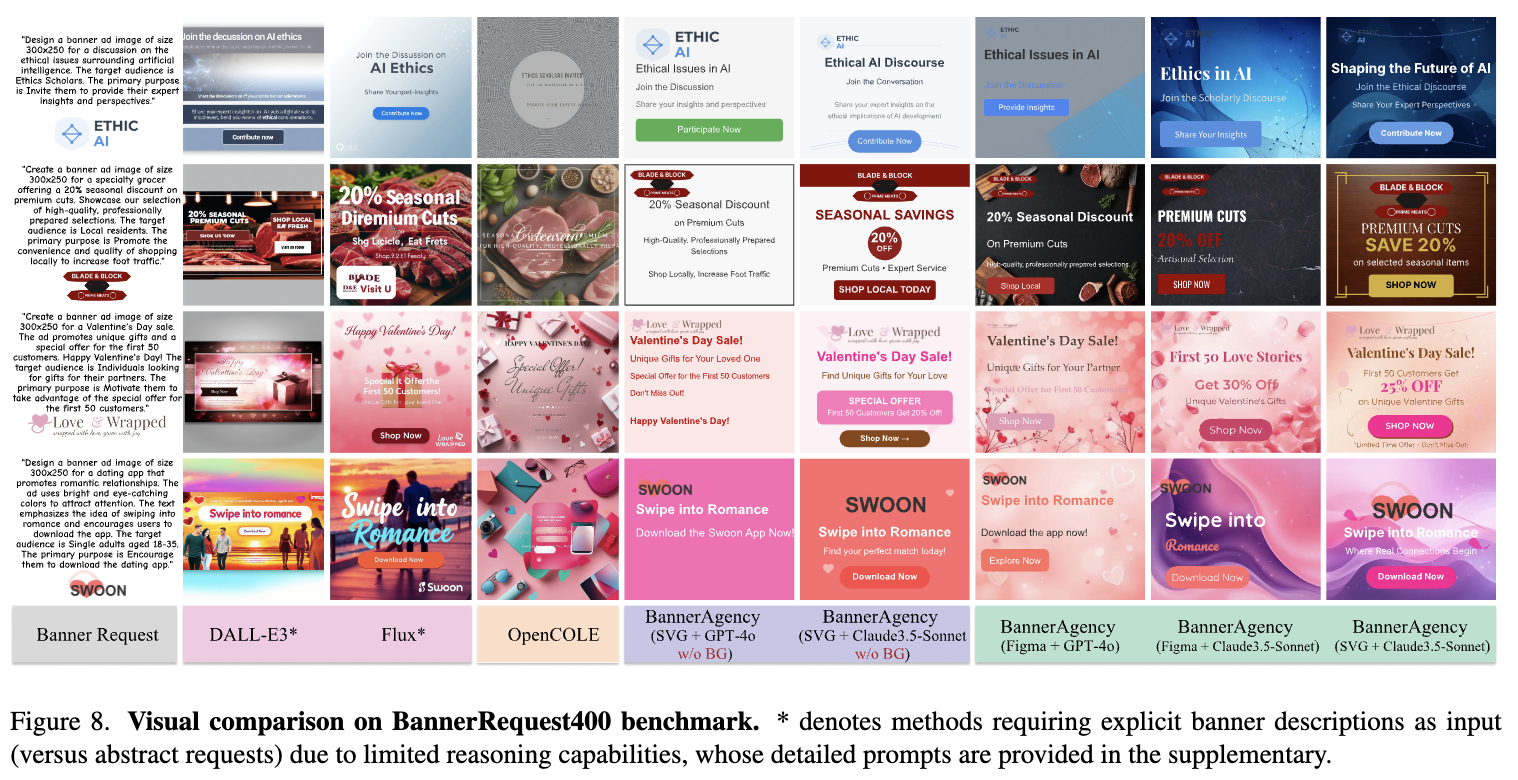

-
정성적 결과 2

-
Refinement에 따른 정량적 & 정성적 결과 분석


- 전반적으로는 우상향하는 결과
- 하지만, 참석자에 따라 initial result를 선호하기도함 $\to$ 전 trajectory를 저장해두고, 선택하도록 해야함
-
Cross-Template-Size
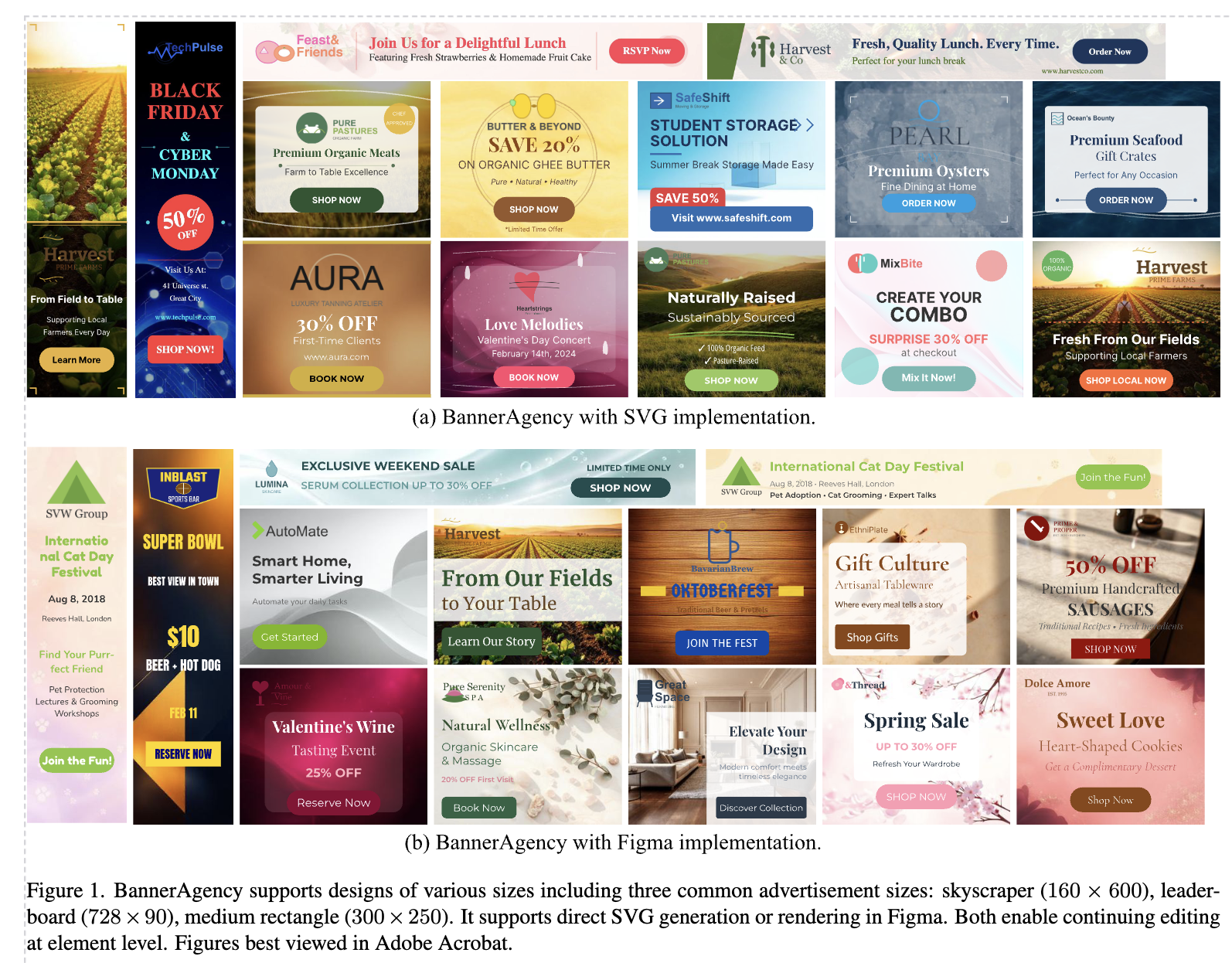
-
Cross-general 정성적 결과

-
Cross-cultural 정성적 결과

-
Different Audience / Same Design Request 예시들
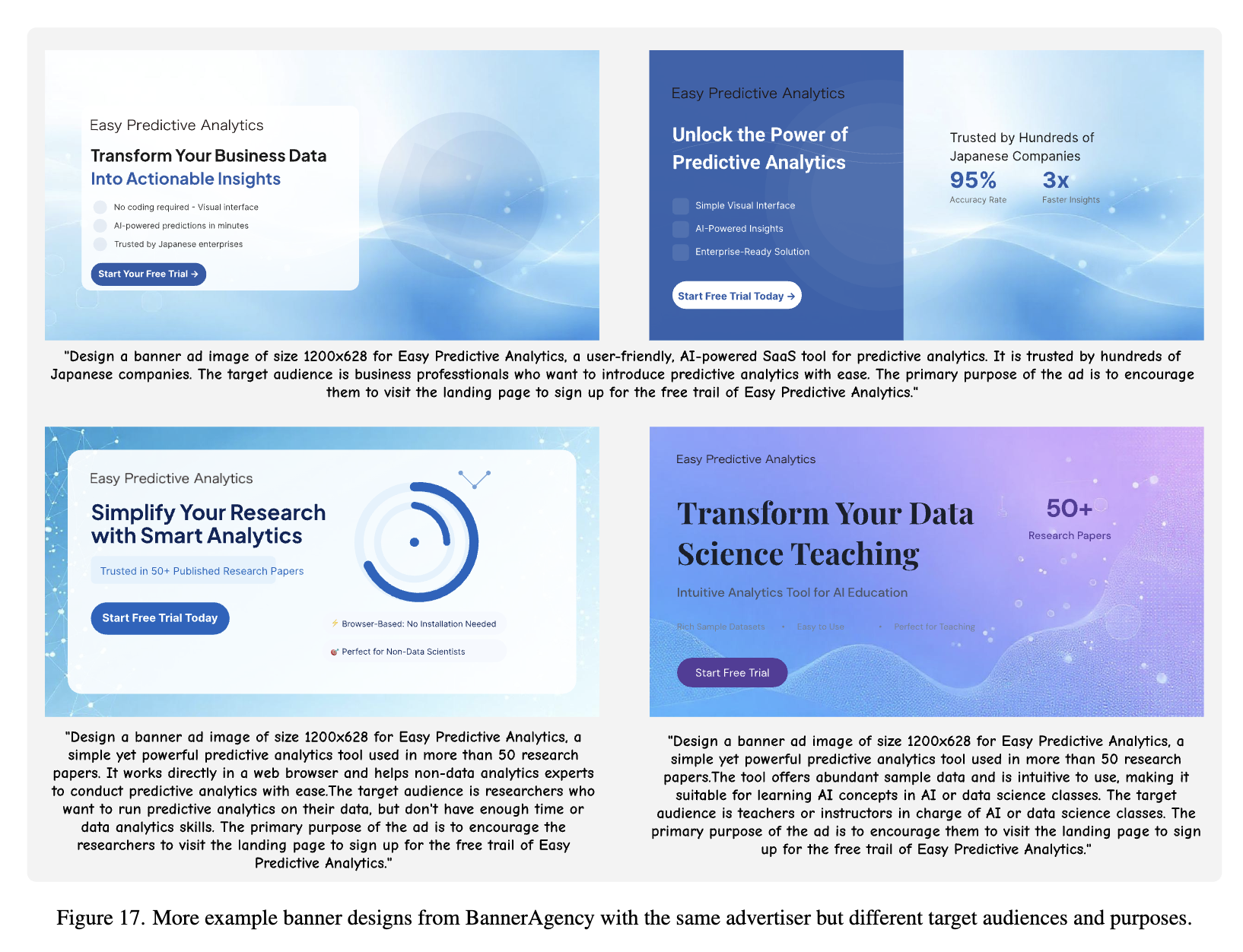
-
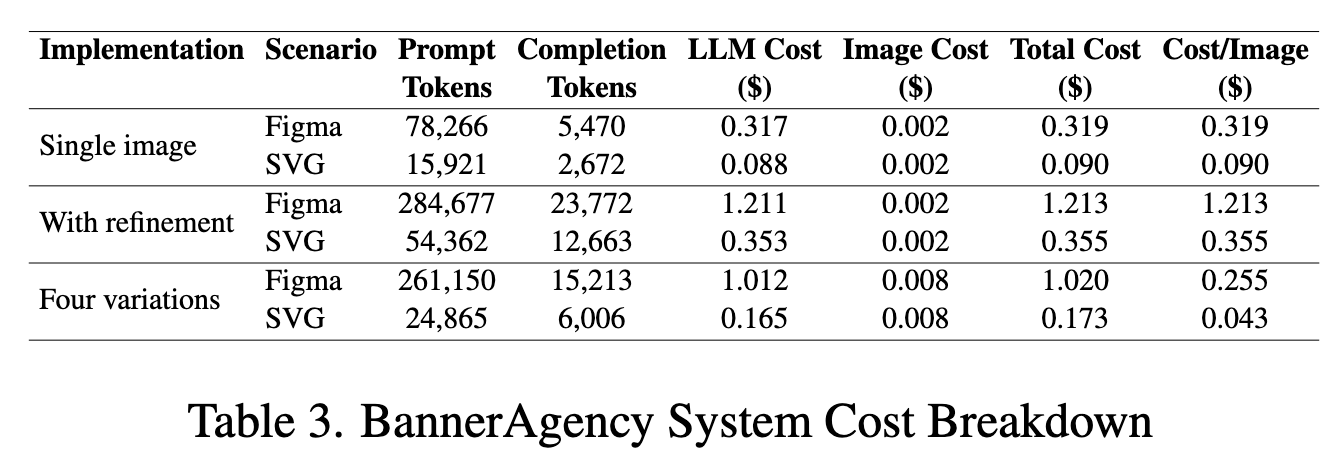
Cost