AesthetiQ: Enhancing Graphic Layout Design via Aesthetic-Aware Preference Alignment of Multi-modal Large Language Models
[Layout] AesthetiQ: Enhancing Graphic Layout Design via Aesthetic-Aware Preference Alignment of Multi-modal Large Language Models
- paper: https://arxiv.org/pdf/2503.00591
- github: X
- CVPR 2025 accepted (인용수: 0회, ‘25-07-03 기준)
- downstream task: Content-aware Layout Generation (Crello, WebUI)
1. Motivation
-
기존의 content-aware layout generation 연구들의 문제점은 심미적인 아름다움을 고려하지 못한 방식으로 레이아웃을 생성함
-
가령, 심미적으로 괜찮은 레이아웃일지라도 CE Loss 방식에서는 아래 예시에서 큰 penalty loss를 줌으로써, 잘못된 방향으로 모델을 학습
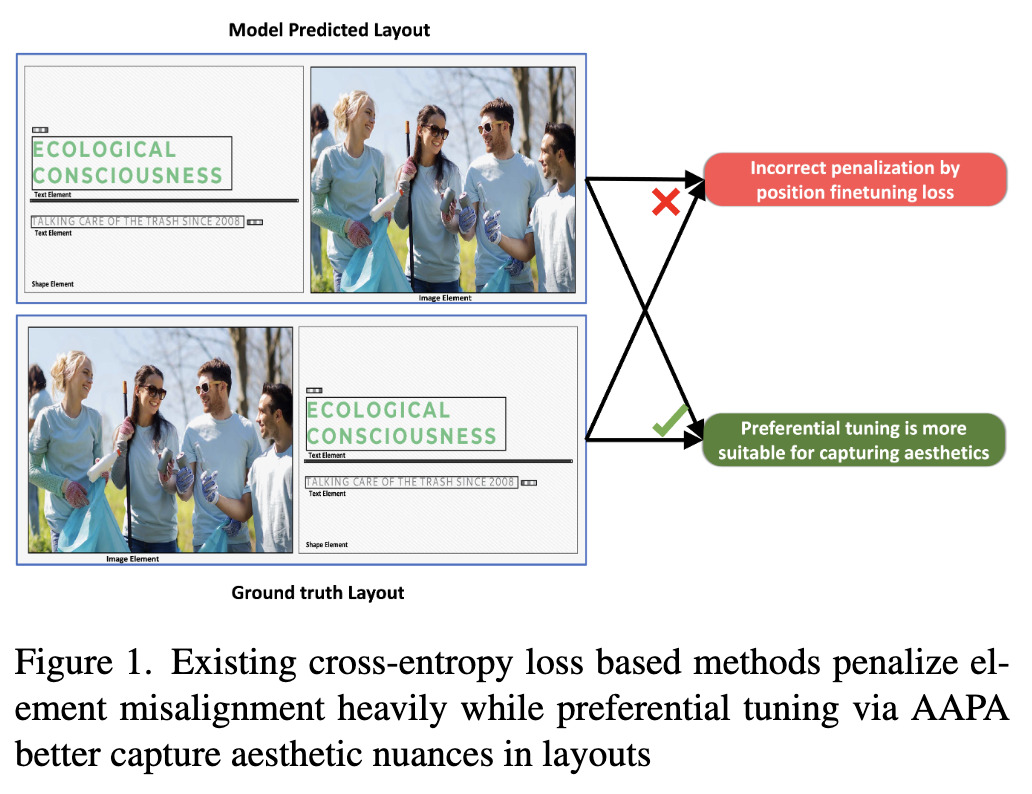
-
-
또한, 사람과 같은 선호도를 고려한 레이아웃을 생성하지 못하고 있음
$\to$ 심미성을 고려한 선호도 최적화 방식을 제안해보자!
2. Contribution
- Direct Preference Optimization (DPO) 방식을 응용한 Aesthetic-Aware Preference Optimization (AAPO) 방식을 제안함
- 여러개의 layout candidate를 생성하고, MLLM-as-a-judge를 활용하여 win-lose layout간의 preference optimization 수행
- 여러 metrics를 filtering 함수로 활용하여 고품질 layout에 대해서만 학습에 활용하는 것의 중요성을 발견
- 새로운 metric을 제안 (MLLM-as-a-aesthetic-scorer 기반 win-rate metric (vs. G.T.))
- 다양한 benchmark 에서 SOTA
3. AesthetiQ
-
Overall Diagram
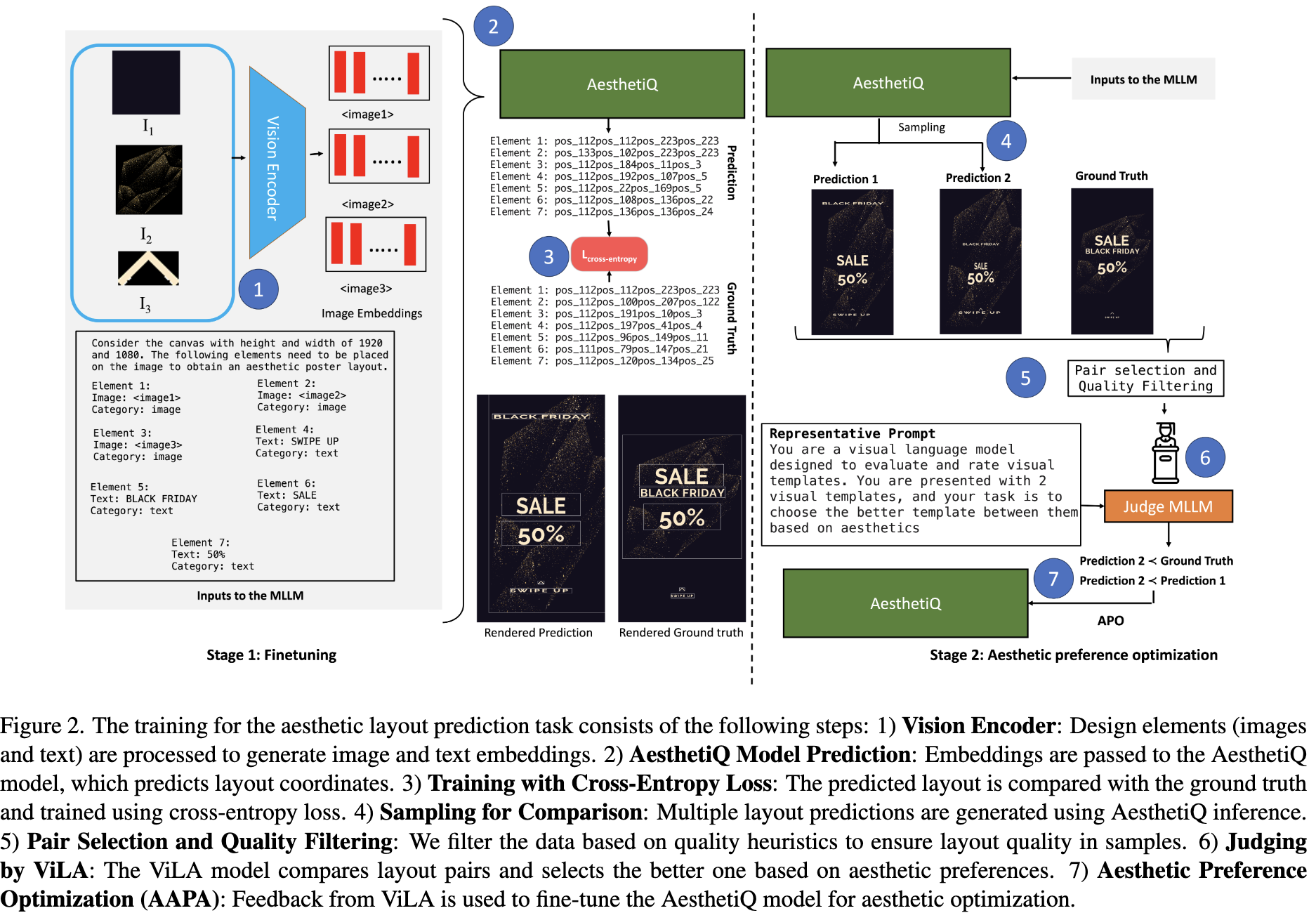
3.1 Layout Prediction Task
- input: 디자인 요소들의 타입, 내용, 캔버스 크기 등의 정보가 담긴 Multi-modal embedding. (훈련 시에는 정답 position token 정보가 학습의 목표로 사용됨)
- output: 입력 정보를 바탕으로 Language Model이 예측한 디자인 요소들의 position token 시퀀스.
Input Prompt Template

- $\mathcal{P}^E_{H_c, W_c}$: 높이 $H_c$와 너비 $W_c$를 가진 캔버스에 대한 입력 프롬프트$(\mathcal{P})$를 나타냄. 이 프롬프트는 디자인 요소$(E)$로 구성.
- $\bigcup_{i=1}^{n}$ 요소 인덱스 (i)가 1부터 (n)까지인 모든 디자인 요소에 대한 연합(union)을 의미. 즉, 모든 (n)개의 디자인 요소로부터 정보를 수집하여 프롬프트를 구성.
- $e_i$: 레이아웃에 포함될 (i)번째 디자인 요소.
- $\mathcal{T}(e_i)$: (i)번째 디자인 요소((e_i))의 타입. 가능한 타입의 집합은 $\mathcal{T}$로 정의되며, {image, text, shape, background}를 포함.
- $\text{ImageTokens}(e_i)$: (i)번째 디자인 요소가 텍스트를 제외한 타입일 경우, 해당 요소를 나타내는 이미지 토큰(Image Tokens)을 의미. 논문에서는 시각 인코더$(f_{vision})$를 통해 이미지 토큰을 임베딩 벡터로 변환.
- $\text{TextTokens}(e_i)$: (i)번째 디자인 요소의 타입이 텍스트((\text{text}))일 경우, 해당 요소를 나타내는 텍스트 토큰(Text Tokens)을 의미. 논문에서는 텍스트 인코더$f_{text}$를 통해 텍스트 토큰을 임베딩 벡터로 변환.
각 요소들의 representation

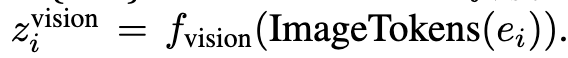
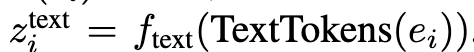
3.2 Position-Aware Layout Instruction Tuning
-
Box $b_i = (x_i, y_i, w_i, h_i)$에 대해 가로, 세로 각각 K개의 bin으로 discretize.
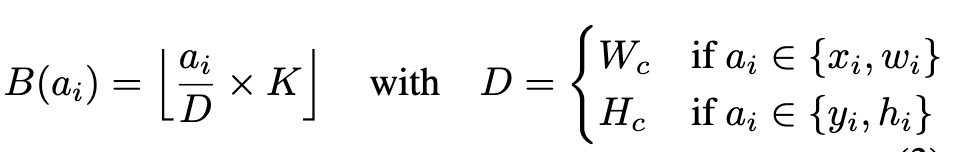
- 각각의 token은 $pos_{B(x_i)}, pos_{B(y_i)}$로 tokenize
-
Supervised Finetuning Loss
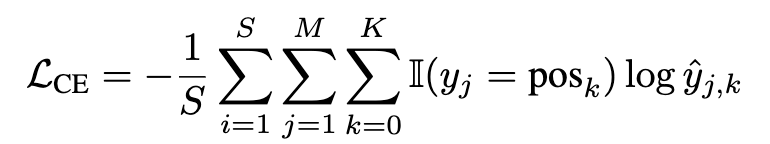
- $y_j$: j번째 element의 정답 token
- $\hat{y_{j,j}}$: j번째 element의 k번째 예측한 position token
3.3 Aesthetic-Aware Preference Alignment
-
개별 요소에 대한 rendering 결과는 미분불가능한 본연의 특성으로 인해 심미적 아름다움의 정도를 학습에 반영하지 못함
-
이를 해결하고자 $M_{judge}$ 를 두어, 여러 pair의 layout에 대해 보고, 그 심미적 score를 결정하도록 함으로써 이 문제 (non-differentiable)를 우회함.
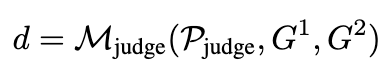
-
$d \in {1,2}$: binary decision which one is better
-
$P_{judge}$: Prompt for judge
-
$G^i=R(E^i, W_c^i, H_c^i)$
-
$E^i$: i번째 (1 or 2) layout
-
$W_c^i, H_c^i$: i번째 canvas width, height
-
$R$: Rendering function
-
$G^i$: Rendering된 이미지
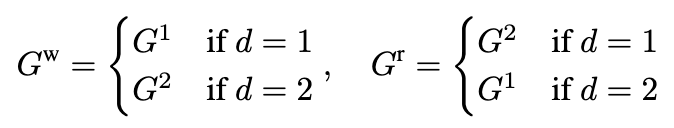
-
$G^w$: best graphi layout
-
$G^r$: worst graphic layout
-
-
-
AAPA Loss

- $\pi_M$: 현재 policy model
- $\pi_{\hat{M}}$: reference model
-
Quality Metircs기반 Layout Filtering
-
고품질 layout이 학습성능에 중요하다고 가정하고, 특정 threshold 이상의 layout만 학습함
-
Align quality
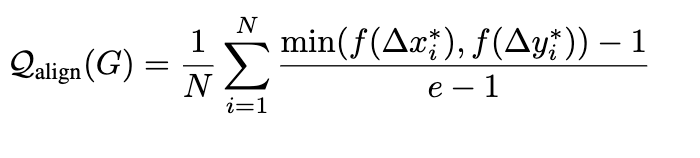
- $e_i$=
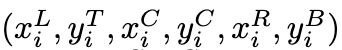
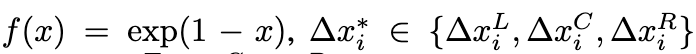
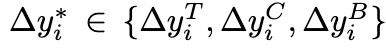
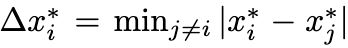
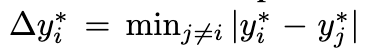
- $e_i$=
-
Overlap quality
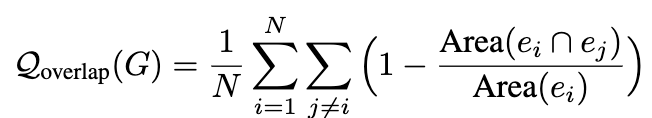
-
Quality score = average (Align Quality, Overlap Quality)
-
-
Threshold
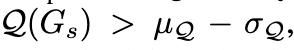
-
-
Aesthetic-Aware Layout Evaluation
-
Test data 의 정답셋과 예측한 layout에 대해 win rate를 매김

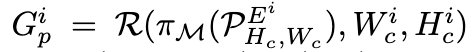
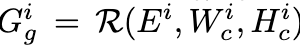
-
3.4 Pretraining to Enhance Layout Understanding
- 80K template dataset를 취득하여 position-aware layout instruction tuning을 학습
4. Experiments
-
Dataset
- Crello (23.3K)
- WebUI (70K)
-
Model : InternVL
-
Evaluation
- Mean IoU (mioU)
- $M_{judge}$ win rate
-
정량적 결과
- Crello

-
WebUI
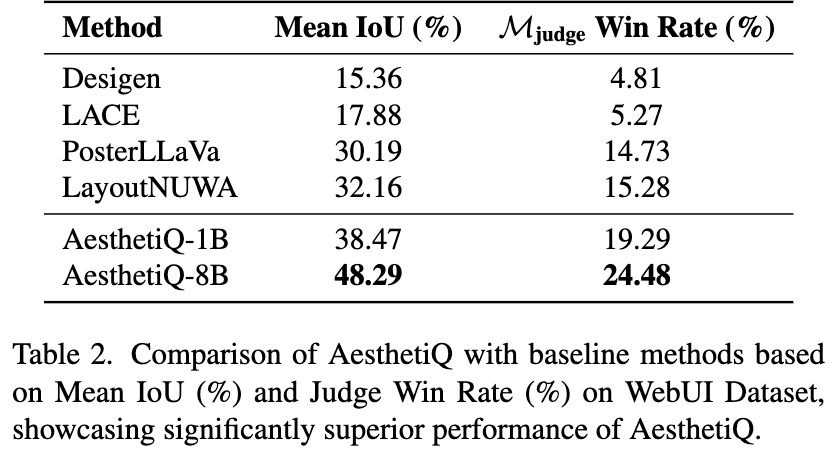
-
정성적 결과
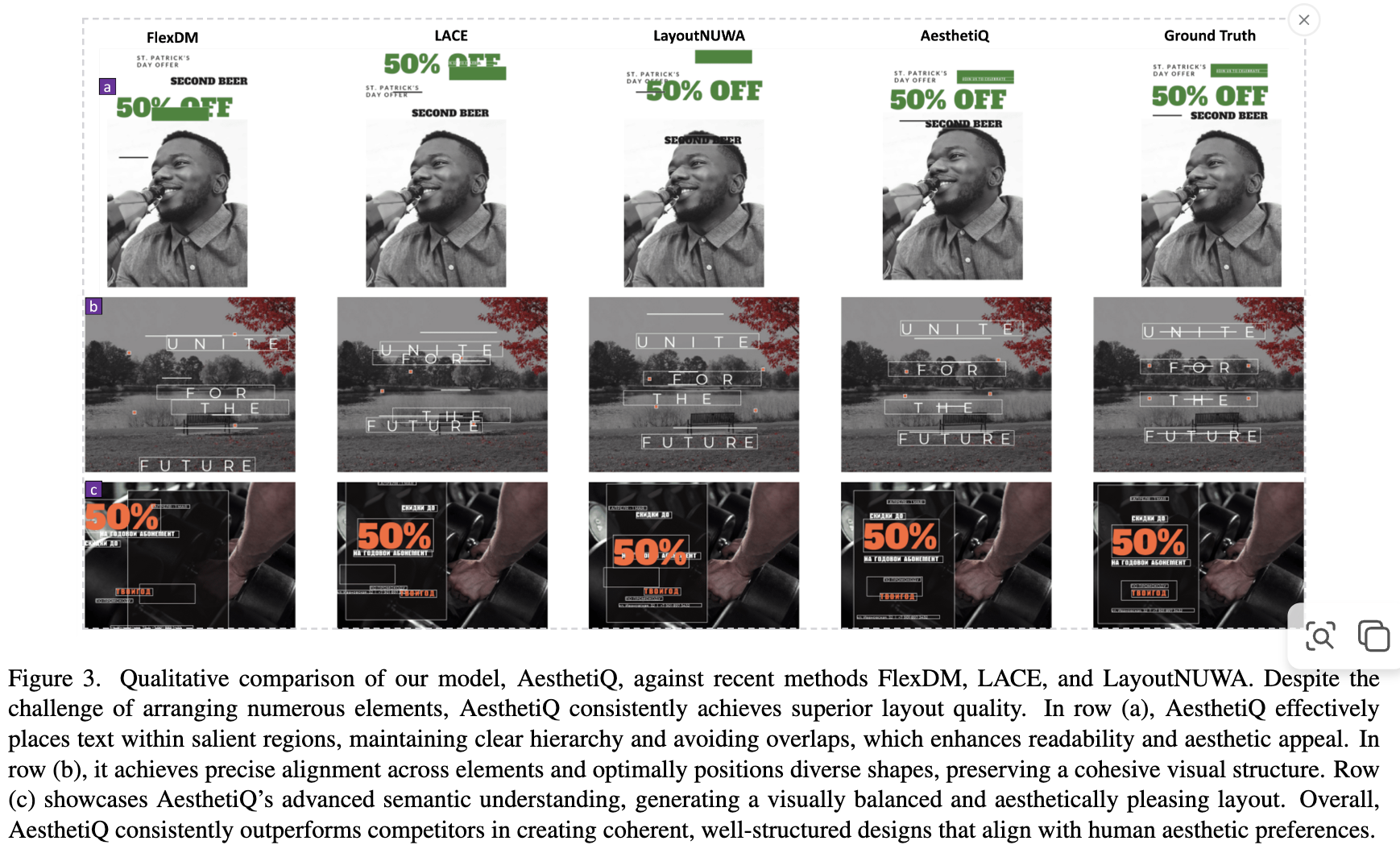
-
Ablation Studies (Model Scale / Pretraining 유무 / Quality Filtering 유무)
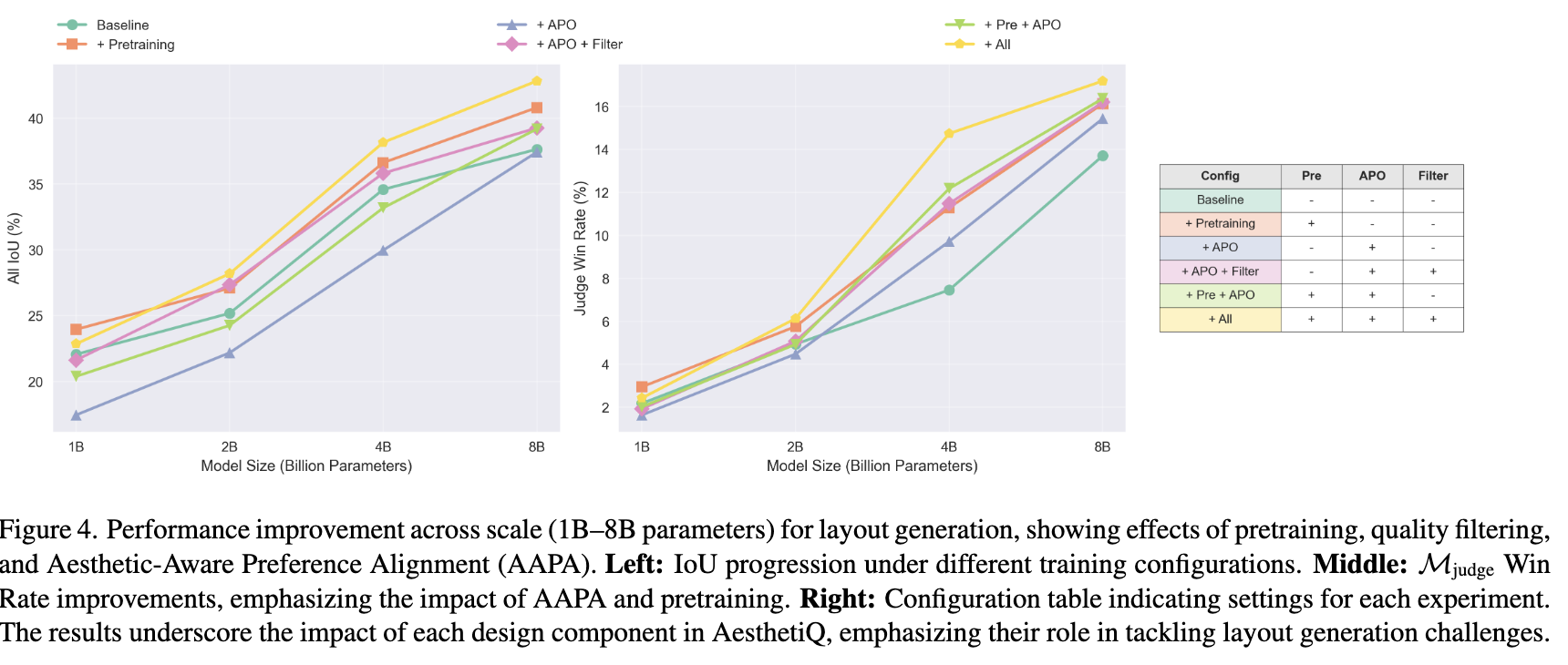
-
다양한 Aspect Ratio에 따른 결과
